- 1. RAG优化概述
- 2. 索引时优化(Index-Time Optimization)
- 3. 检索前优化(Pre-Retrieval Optimization)
- 3.1 伪文档生成法(Query-to-Document)
- 3.2 假设文档向量化(Assume Document Vectorization / HyDE)
- 3.3 问题分解策略(Sub-Question Decomposition)
- 3.4 多角度查询重写(Query Rewriting)
- 3.5 抽象化查询转换(Take a Step Back)
- 3.6 检索-生成一体化(Retrieval-generation Integration)
- 3.7 上下文对话(Contextual Dialogue / Agentic RAG)
- 3.8 行业场景改写(Industry Scenario Adaptation)
- 3.9 Text2SQL
- 4. 检索后优化(Post-Retrieval Optimization)
- 5. 系统级优化(System-Level Optimization)
- 6. 技术选型建议
- 7. 总结
1. RAG优化概述 #
检索增强生成(Retrieval-Augmented Generation, RAG)系统通过结合外部知识库检索和大语言模型生成,实现了知识密集型任务的智能问答。为了提升RAG系统的性能,可以从索引时、检索前、检索后和系统级四个维度进行优化。本文档系统梳理了这四个阶段的优化技术,为构建高效、准确的RAG系统提供全面指导。
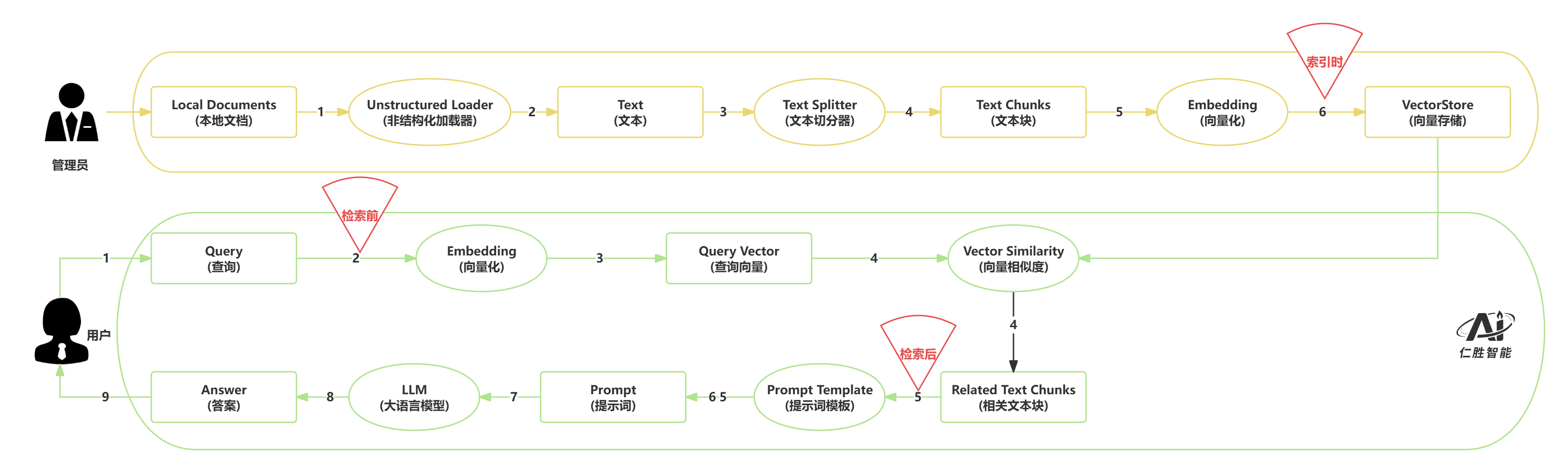
2. 索引时优化(Index-Time Optimization) #
索引时优化是在文档入库阶段对原始文档进行预处理和结构化,以提升后续检索的精度和效率。
2.1 层次化文档索引(Hierarchical Document Indexing) #
核心思想:将大文档块(parent chunks)细分为更小的子块(child chunks),用子块进行向量化检索,但返回父块内容以保持上下文完整性。
技术流程:
- 文档先切分为父块(如300字符)
- 每个父块再细分为子块(如100字符)
- 对子块进行向量化并建立索引
- 检索时用子块匹配,返回对应的父块内容
优势:
- 提高检索精度:短文本更容易与用户问题产生精确匹配
- 保持上下文完整性:返回大块内容,避免信息碎片化
- 平衡存储与召回:子块索引数量可控,同时保证检索效果
适用场景:长文档、章节性强的文本、复杂报告等需要细粒度匹配但又要保持上下文连贯的场景。
2.2 摘要化索引(Abstracted Index) #
核心思想:使用LLM为每个文档块生成摘要,对摘要进行向量化索引,检索时用摘要匹配,返回原始文档块。
技术流程:
- 文档分块(如300字符/块)
- 对每个块调用LLM生成摘要
- 将摘要向量化并存入向量库
- 检索时匹配摘要,返回原始文档块
优势:
- 检索精度提升:摘要浓缩关键信息,使相关性检索更聚焦
- 兼容抽象性查询:用户提问较抽象时,摘要更易匹配
- 召回完整上下文:最终返回原始文档块,便于生成链使用
适用场景:长文档、高冗余知识库、多主题多专业领域的RAG系统。
2.3 问题化索引(Hypothetical Question Index) #
核心思想:为每个文档块生成若干个假设性问题,对问题进行向量化索引,检索时用"问题vs问题"的方式匹配,返回原始文档块。
技术流程:
- 文档分块
- 为每个块生成2-5个假设性问题(确保答案能在原文中找到)
- 将问题向量化并建立索引
- 检索时用户问题与假设性问题匹配,返回原始文档块
优势:
- 问题表达适配查询:假设性问题形态与用户输入自然对齐
- 保障原文完整性:只用问题做索引,返回时提供原始chunk
- 灵活性强:支持为每个文档生成多个问题,覆盖不同问法
适用场景:用户查询多为问题形式,需要提升"问题-问题"匹配精度的场景。
3. 检索前优化(Pre-Retrieval Optimization) #
检索前优化是在执行检索之前对用户查询进行增强、改写或分解,以提升检索的召回率和相关性。
3.1 伪文档生成法(Query-to-Document) #
核心思想:用户输入查询后,先用LLM生成一段伪文档(包含解释、背景、关键词等),将原始查询与伪文档拼接形成增强查询,再进行检索。
技术流程:
- 调用LLM根据用户查询生成伪文档
- 将伪文档与原始查询拼接
- 对增强后的查询进行向量化检索
优势:
- 语义丰富化:伪文档包含回答所需的关键信息
- 关键词扩展:增加检索词汇,提升稀疏检索效果
- 上下文补充:为原始查询提供必要的背景信息
适用场景:用户输入模糊、信息不足的查询,面向多领域或大规模知识库。
3.2 假设文档向量化(Assume Document Vectorization / HyDE) #
核心思想:生成多个不同角度的假设文档,将它们向量化后与原始查询向量进行平均,使用平均向量进行检索。
技术流程:
- 生成3个不同角度的假设文档(如学术、应用、基础概念)
- 将原始查询和所有假设文档分别向量化
- 计算所有向量的算术平均值
- 使用平均向量进行检索
优势:
- 多角度语义覆盖:通过不同角度的假设文档,提升语义空间覆盖范围
- 向量空间优化:平均向量在语义空间中更接近目标文档
- 检索精度提升:增强后的查询向量具有更好的检索召回率
适用场景:高度开放性问题、复杂信息需求聚合型检索。
3.3 问题分解策略(Sub-Question Decomposition) #
核心思想:将复杂问题拆解为多个子问题,每个子问题独立检索,合并结果后生成最终答案。
技术流程:
- 使用LLM将复杂问题拆解为3-5个子问题
- 对每个子问题分别进行向量检索
- 合并所有检索结果并去重
- 基于所有检索信息生成最终答案
优势:
- 复杂多层次查询:针对包含多个子问题的复杂查询
- 语义信息保护:避免直接检索导致的语义信息丢失
- 全面覆盖:确保原始问题的所有方面都得到处理
适用场景:包含并列/递进若干小问的查询、复杂链式推理问题。
3.4 多角度查询重写(Query Rewriting) #
核心思想:生成多个不同表达方式的查询版本,并行检索后合并结果。
技术流程:
- 使用LLM生成3-5个不同表达方式的查询版本
- 使用所有查询版本同时进行知识库检索
- 将多个检索结果合并并去重
- 基于整合的上下文生成最终答案
优势:
- 查询质量提升:通过多角度重写解决表达问题
- 检索覆盖增强:多个查询版本提供更全面的检索覆盖
- 上下文丰富化:整合多个检索结果形成更丰富的上下文
- 容错能力强:具有完善的错误处理机制
适用场景:用户表达简略、查询存在同义/多义、问题较模糊或抽象。
3.5 抽象化查询转换(Take a Step Back) #
核心思想:将具体问题转化为更高层次的抽象问题,使用抽象查询进行广泛检索,原始查询进行精确检索,混合检索后合并结果。
技术流程:
- 使用LLM将具体问题转化为抽象问题
- 使用抽象化查询进行广泛检索(5个结果)
- 使用原始查询进行精确检索(3个结果)
- 合并检索结果并去重
- 基于混合检索结果生成最终答案
优势:
- 提升召回率:抽象化查询能够匹配更多相关文档
- 减少过拟合:避免因具体细节导致的检索偏差
- 增强泛化性:提高系统对类似问题的处理能力
适用场景:教育问答、技术原理解读、流程方法通用性归纳、案例"举一反三"。
3.6 检索-生成一体化(Retrieval-generation Integration) #
核心思想:在检索前进行意图分类和查询重写,根据业务场景动态选择知识库和检索策略。
技术流程:
- 意图识别:判断用户问题的类型(如假期政策、调岗流程等)
- 查询重写:将口语化问题转换为标准术语
- 多知识库检索:根据意图检索对应的知识库
- 答案生成:基于检索结果生成最终答案
优势:
- 检索和生成协同优化:根据业务场景定制检索逻辑
- 提升准确率:意图识别和查询重写显著提升检索准确性
- 灵活可扩展:支持多知识库、多意图场景
适用场景:企业私有知识库、多业务场景的智能问答系统。
3.7 上下文对话(Contextual Dialogue / Agentic RAG) #
核心思想:结合多轮对话历史,智能解析和补全当前用户意图,生成更精准的检索查询。
技术流程:
- 维护对话历史记录
- 使用Agent分析对话历史和最新问题
- 生成1到多条适合知识库检索的query
- 对每个query进行检索,合并结果
- 基于历史对话和检索结果生成答案
优势:
- 指代消解:自动识别"它"、"这个"等指代词的具体对象
- 缺省信息补全:自动补充上下文条件
- 多轮追问/比较:支持对比型、条件型等复杂对话
适用场景:多轮对话场景、需要上下文理解的智能问答系统。
3.8 行业场景改写(Industry Scenario Adaptation) #
核心思想:针对不同行业(教育、医疗、法律等)的提问习惯和术语表达,对查询进行行业适配改写。
技术流程:
- 识别行业类型
- 使用行业适配器对查询进行改写
- 使用改写后的查询进行检索
- 生成行业相关的答案
优势:
- 提升行业检索召回率与准确率:有针对性地处理行业术语
- 降低生成压力:让生成任务聚焦在精要的检索片段上
- 方便扩展:只需增加新行业的适配器即可复用
适用场景:垂直行业知识库、专业领域问答系统。
3.9 Text2SQL #
核心思想:将自然语言查询转换为SQL语句,直接在结构化数据库中检索。
技术流程:
- 槽位提取:从自然语言中提取结构化条件
- 对话状态管理:维护多轮对话中的槽位状态
- 冲突检测:检测新旧槽位之间的冲突
- SQL生成:根据槽位生成SQL查询语句
- 执行查询并生成自然语言答案
优势:
- 精确筛选:支持多条件组合查询
- 多轮对话:支持逐步补充和修正条件
- 冲突处理:自动识别并处理条件矛盾
适用场景:结构化数据库查询、招聘管理、客户管理等需要精确筛选的业务场景。
4. 检索后优化(Post-Retrieval Optimization) #
检索后优化是在获得初步检索结果后,对文档进行压缩、融合或重排序,以提升最终答案的质量。
4.1 上下文压缩(Contextual Compression) #
核心思想:对检索到的文档基于用户查询进行压缩,只保留与查询相关的关键信息,去除无关内容。
技术流程:
- 向量检索获得候选文档
- 对每个文档使用LLM进行上下文压缩
- 只保留压缩后有内容的文档
- 将压缩后的文档拼接成上下文,生成答案
优势:
- 大幅提升上下文利用率:压缩后可纳入更多相关知识点
- 噪声过滤和内容聚焦:自动去除无用背景信息
- 提升推理推断能力:短小精炼的上下文有助于LLM串联信息
- 节省推理算力和上下文窗口:同样token预算下能包含更多知识
适用场景:多轮长对话、法律/医学/学术等长文案场景、通用RAG问答系统。
4.2 混合检索(Hybrid Retrieval) #
核心思想:结合稀疏检索(BM25)和密集检索(向量检索),通过加权融合提升检索效果。
技术流程:
- 并行执行BM25稀疏检索和向量密集检索
- 使用加权导数排名算法计算融合分数
- 按融合分数排序,返回top-k文档
融合算法:
- 公式:融合分数 = 1 / (k + rank)
- 排名越靠前的文档,融合分数越高
- 最终分数 = 稀疏分数 × 稀疏权重 + 密集分数 × 密集权重
优势:
- 鲁棒性强:通过多方法融合,降低单一方法的局限性
- 适应性好:可根据具体应用场景调整权重分配
- 精度提升:结合关键词匹配和语义理解,提高检索准确性
适用场景:复杂多变的查询需求、需要兼顾精确匹配和语义理解的场景。
4.3 文档重排序(Document Reranking) #
核心思想:先用向量检索召回候选文档,再用Cross-Encoder或LLM对查询-文档对进行相关性精细打分,重新排序。
技术流程:
- 向量检索召回多个候选文档(如10-20条)
- 对每个"查询-文档"对使用Cross-Encoder或LLM进行相关性评分
- 按分数从高到低排序
- 只保留最相关的前几条(如Top-3/Top-4)进入生成环节
优势:
- 有效过滤干扰文档:能过滤掉表面相似但实际不相关的文档
- 极大改善答案准确度:提升RAG系统的答案准确度、可控性和鲁棒性
- 计算代价可控:通常只需重排序少量文档
适用场景:高精度问答/助理型RAG系统、法律/医疗/金融等对精准文档匹配强依赖的领域。
5. 系统级优化(System-Level Optimization) #
系统级优化是从整体架构和流程设计角度,通过迭代、自判别等机制提升RAG系统的整体性能。
5.1 迭代式检索增强(Iterative Retrieval) #
核心思想:通过多次完整的RAG流程迭代来逐步提升答案质量,每次迭代都基于前一次的结果进行优化。
技术流程:
- 第一次迭代:接收用户原始问题,检索获得初始上下文,生成初步答案
- 第二次迭代:将第一次迭代的答案与原始问题合并,形成新的查询,重新检索,生成最终答案
- 可进行更多次迭代,每次迭代策略相同
优势:
- 信息累积效应:每次迭代都能从之前的答案中提取有价值的信息
- 检索精度提升:补充信息有助于检索到更相关的文档
- 答案质量改善:基于更准确的上下文生成更可靠的答案
- 错误修正能力:后续迭代能够纠正前面迭代中的不准确信息
适用场景:复杂问题、需要多步骤推理或信息整合的场景。
5.2 智能自判别检索增强(SelfRAG) #
核心思想:在RAG的每个关键节点嵌入智能判别模块,通过实时评估来动态调整策略选择。
技术流程:
- 文档相关性判别:智能判断返回的文档与用户问题的相关程度,筛选高相关性文档
- 查询增强:当检索结果不理想时,触发查询增强策略
- 答案生成:基于筛选后的文档生成答案
- 答案可信度验证:
- 上下文支持度检查:验证答案是否能在文档中找到依据
- 问题解答完整性:评估答案是否真正解决了用户问题
- 动态策略选择:根据验证结果决定是否重新生成或返回
优势:
- 大幅提升答案正确率、完整性和鲁棒性
- 智能质量控制:在每个关键节点进行实时评估
- 动态策略调整:根据判别结果自动调整检索和生成策略
适用场景:知识分布广且不均匀、文档片段质量参差不齐、结果要求高准确性高覆盖率的场景。
6. 技术选型建议 #
6.1 按场景选择优化技术 #
简单问答场景:
- 索引时:层次化文档索引
- 检索前:查询重写
- 检索后:文档重排序
复杂多轮对话场景:
- 索引时:摘要化索引
- 检索前:上下文对话、问题分解
- 检索后:上下文压缩
- 系统级:迭代式检索增强
专业领域场景:
- 索引时:问题化索引
- 检索前:行业场景改写、检索-生成一体化
- 检索后:混合检索、文档重排序
- 系统级:SelfRAG
结构化数据查询场景:
- 检索前:Text2SQL
6.2 技术组合策略 #
基础组合:
- 层次化文档索引 + 查询重写 + 文档重排序
进阶组合:
- 摘要化索引 + 问题分解 + 混合检索 + 上下文压缩
高级组合:
- 问题化索引 + 上下文对话 + 混合检索 + 文档重排序 + SelfRAG
6.3 性能与成本权衡 #
低成本方案:
- 索引时优化(一次性成本)
- 查询重写(低计算成本)
中等成本方案:
- 混合检索(中等计算成本)
- 文档重排序(需要额外模型推理)
高成本方案:
- 上下文压缩(需要多次LLM调用)
- 迭代式检索增强(多次完整RAG流程)
- SelfRAG(多次判别和生成)
7. 总结 #
RAG优化技术涵盖了从文档索引到答案生成的完整流程,每个阶段都有其独特的优化价值:
- 索引时优化:通过预处理和结构化,为后续检索奠定良好基础
- 检索前优化:通过查询增强和改写,提升检索的召回率和相关性
- 检索后优化:通过压缩、融合和重排序,提升最终答案的质量
- 系统级优化:通过迭代和自判别,从整体架构角度提升系统性能
在实际应用中,应根据具体场景和需求,选择合适的优化技术组合,在性能、成本和复杂度之间取得平衡。随着RAG技术的不断发展,这些优化方法也在持续演进和完善,为构建更智能、更准确的问答系统提供强大支撑。