12. LengthBasedExampleSelector #
背景说明
- 在 few-shot 提示(Few-shot Prompting)应用场景下,我们通常会给模型若干个“示例”来展现问题与回答的范例,从而让模型更好地理解如何作答。
- 但在实际应用中,支持的最大提示长度(token/w数或字符数)是有限的。
- 当输入较长时,能容纳的示例数就会变少,否则会超出最大长度限制。因此,如何“自适应”地选取尽可能多但又不超长的示例,是提升提示工程自动化和健壮性的关键。
LengthBasedExampleSelector 就是为了解决上述问题设计的自动示例选择器。其核心逻辑如下:
- 预先缓存所有示例格式化后的长度,以便快速评估添加每个示例后的总长度。
- 动态根据当前输入长度和最大提示词长度上限,自动选择最多、但不超限的示例数量。
- 支持自定义文本长度计算方式(如按词、按字符、按token等)。
- 可直接与
FewShotPromptTemplate集成,让 few-shot 提示自动适应各种实际输入场景。
工作流程
初始化 Selector
- 需要传入所有样例、样例格式模板、最大总长度,以及可选的自定义长度计算函数。
- 对所有样例(格式化后)预先计算并缓存其长度,便于后续快速累计。
示例选择逻辑
- 输入变量(如用户问题)到来时,先用长度函数统计输入部分的“消耗”。
- 用
max_length减去输入长度,得出剩余可用长度。 - 按顺序尝试依次加入样例,每加入一个都会检查累计长度是否超过剩余可用长度。超了就停止,不再添加。
- 最终返回所有未超长的已选样例。
与 FewShotPromptTemplate 配合
- 在使用
FewShotPromptTemplate时,将 selector 作为example_selector传入即可。 - 模板会自动调用 selector,根据实际输入来动态选择合适的 few-shot 示例。
- 在使用
应用场景举例
- 用户短问题,剩余长度充足,可以多给几个范例,提升效果。
- 用户长问题或多轮上下文,自动减少 few-shot 示例,保证不超长,避免报错。
注意事项
- 默认长度计算按“单词数”,如需更精细(如按中文字符或token数),可自定义
get_text_length函数(如用 tiktoken/tokenizers 库)。 - 示例顺序也会影响挑选(优先选前面的);如需智能排序,可自行在 examples 列表中调整。
总结
相比传统静态 few-shot 示例,LengthBasedExampleSelector 能更智能、更健壮地对齐实际需求,兼顾效果最大化和安全性,非常适合生产环境下的 LLM 提示工程实践。
12.1. 12.LengthBasedExampleSelector.py #
12.LengthBasedExampleSelector.py
# 导入 PromptTemplate 和 FewShotPromptTemplate,用于生成提示模板
#from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
# 导入 LengthBasedExampleSelector,用于基于长度自动选择示例
#from langchain_core.example_selectors import LengthBasedExampleSelector
# 导入 ChatOpenAI,用于调用 OpenAI 的聊天大模型
#from langchain_openai import ChatOpenAI
# 从 smartchain.chat_models 模块引入 ChatOpenAI,用于构建大模型接口
from smartchain.chat_models import ChatOpenAI
# 从 smartchain.prompts 模块引入 PromptTemplate 和 FewShotPromptTemplate,用于构建提示模板
from smartchain.prompts import PromptTemplate, FewShotPromptTemplate
# 从 smartchain.example_selectors 模块引入 LengthBasedExampleSelector, 用于自动选择合适示例
from smartchain.example_selectors import LengthBasedExampleSelector
# 定义一个包含多个问答对的列表,每个元素是一个字典,表示一个示例
examples = [
{"question": "1 plus 1等于多少?", "answer": "答案是2"},
{"question": "2 plus 2等于多少?", "answer": "答案是4"},
{"question": "3 plus 3等于多少?", "answer": "答案是6"},
{"question": "4 plus 4等于多少?", "answer": "答案是8"},
{"question": "5 plus 5等于多少?", "answer": "答案是10"},
]
# 定义示例展示的格式模板,通过 from_template 方法快速构建
example_prompt = PromptTemplate.from_template(
"问题:{question}\n答案:{answer}"
)
# 创建 LengthBasedExampleSelector,用于按照总长度自动选择若干示例
# max_length 设置为较小值(15),方便演示输入长度不同对示例数目的影响
selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=15,
)
# 构造两个用于测试的不同长度的输入,用于观察选择器行为
test_inputs = [
# 短输入:可以选取较多示例
{"user_question": "6 plus 6等于多少?"},
# 长输入:只能选取少量示例
{"user_question": "这是一个非常长的问题,用来测试当输入很长时,示例选择器会选择更少的示例,因为剩余的长度更少了。"},
]
# 构建 FewShotPromptTemplate,自动根据输入长度选择合适的示例,无需再传 examples
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt,
prefix="你是一个数学助手。以下是一些示例:",
suffix="问题:{user_question}\n答案:",
example_selector=selector
)
# 使用 FewShotPromptTemplate 格式化文本,实际填充示例和用户输入
formatted = few_shot_prompt.format(user_question="7 plus 7等于多少?")
# 打印出格式化好的 prompt,方便检查示例引用和输入拼接效果
print(formatted)
# 创建 OpenAI 聊天模型实例,使用 gpt-4o 模型
llm = ChatOpenAI(model="gpt-4o")
# 通过大模型接口调用,生成对用户问题的回答
result = llm.invoke(formatted)
# 输出模型生成的答案内容
print(result.content)
12.2. example_selectors.py #
smartchain/example_selectors.py
from abc import ABC, abstractmethod
from .prompts import PromptTemplate
import re
import tiktoken
# 定义示例选择器的抽象基类
class BaseExampleSelector(ABC):
"""示例选择器的抽象基类"""
@abstractmethod
def select_examples(self, input_variables: dict) -> list[dict]:
"""根据输入变量选择示例"""
pass
# 定义一个基于长度的示例选择器类
class LengthBasedExampleSelector(BaseExampleSelector):
"""
基于长度的示例选择器
根据输入长度自动选择合适数量的示例,确保总长度不超过限制
"""
# 构造方法,初始化LengthBasedExampleSelector对象
def __init__(
self,
examples: list[dict], # 示例列表,每个元素为字典
example_prompt: PromptTemplate | str, # 用于格式化示例的模板,可以是PromptTemplate或字符串
max_length: int = 2048, # 提示词最大长度,默认为2048
get_text_length=None, # 可选的文本长度计算函数
):
"""
初始化 LengthBasedExampleSelector
Args:
examples: 示例列表,每个示例是一个字典
example_prompt: 用于格式化示例的模板(PromptTemplate 或字符串)
max_length: 提示词的最大长度(默认 2048)
get_text_length: 计算文本长度的函数(默认按单词数计算)
"""
# 保存所有示例到实例变量
self.examples = examples
# 如果example_prompt是字符串,则构建为PromptTemplate对象
if isinstance(example_prompt, str):
self.example_prompt = PromptTemplate.from_template(example_prompt)
# 如果已是PromptTemplate则直接赋值
else:
self.example_prompt = example_prompt
# 保存最大长度参数
self.max_length = max_length
# 设置文本长度计算函数,默认为内部定义的按单词数计算
self.get_text_length = get_text_length or self._get_default_length
# 计算并缓存每个示例(格式化后)的长度
self.example_text_lengths = self._calculate_example_lengths()
# 默认的长度计算方法,统计文本中的单词数
def _get_default_length(self, text: str) -> int:
"""
默认的长度计算函数:按单词数计算
Args:
text: 文本内容
Returns:
文本长度(单词数)
"""
# 利用正则按空白字符分割,统计词数
return len(re.split(r'\s+', text.strip()))
# 默认的长度计算方法,统计文本中的单词数
def _get_words_length(self, text: str) -> int:
words = jieba.cut(text)
list = [word for word in words if word.strip()]
return len(list)
def _get_token_length(self, text: str) -> int:
tokens = encoder.encode(text)
return len([token for token in tokens])
# 计算所有示例格式化后的长度
def _calculate_example_lengths(self) -> list[int]:
"""
计算所有示例的长度
Returns:
每个示例的长度列表
"""
# 初始化长度列表
lengths = []
# 对每个示例进行格式化并计算长度
for example in self.examples:
# 用模板对示例内容进行格式化
formatted_example = self.example_prompt.format(**example)
# 计算格式化后示例的长度
length = self.get_text_length(formatted_example)
# 记录到列表中
lengths.append(length)
# 返回长度列表
return lengths
# 根据输入内容长度,选择合适的示例列表
def select_examples(self, input_variables: dict) -> list[dict]:
"""
根据输入长度选择示例
Args:
input_variables: 输入变量字典
Returns:
选中的示例列表
"""
# 将输入的所有变量拼成一个字符串
input_text = " ".join(str(v) for v in input_variables.values())
# 计算输入内容的长度
input_length = self.get_text_length(input_text)
# 计算剩余可用长度
remaining_length = self.max_length - input_length
# 初始化选中的示例列表
selected_examples = []
# 遍历所有示例
for i, example in enumerate(self.examples):
# 如果剩余长度已经不足,提前停止选择
if remaining_length <= 0:
break
# 获取当前示例的长度
example_length = self.example_text_lengths[i]
# 判断如果再添加这个示例会超过剩余长度,则停止选择
if remaining_length - example_length < 0:
break
# 把当前示例加入已选择列表
selected_examples.append(example)
# 更新剩余可用长度
remaining_length -= example_length
# 返回最终选中的示例列表
return selected_examples
# 导入 tiktoken 库(用于分词和获取 token 编码器)
import tiktoken
# 获取名为 "cl100k_base" 的编码器实例
encoder = tiktoken.get_encoding("cl100k_base")
# 要进行编码的文本内容
text = "8 plus 7 等于多少?"
# 对文本内容进行分词和编码,得到 token 的 id 列表
tokens = encoder.encode(text)
# 打印编码得到的全部 token id 列表
print(f"Token IDS:{tokens}")
# 准备一个空列表用于后续保存每个 token 解码后的字符串
token_strings = []
# 遍历每个 token id
for token in tokens:
# 通过 id 解码为单个 token 对应的字节数组
token_bytes = encoder.decode_single_token_bytes(token)
# 尝试使用 utf-8 编码将字节数组解码成字符串(遇到非法字符直接忽略)
token_str = token_bytes.decode("utf-8", errors='ignore')
# 把每个 token 解码后的字符串存进列表
token_strings.append(token_str)
# 打印所有 token 解码得到的字符串列表
print(f"token_strings:{token_strings}")
# 统计并打印有效 token 字符串的个数(去除空白和空字符串)
print(f"length:{len([item for item in token_strings if item and item.strip()])}")12.3. prompts.py #
smartchain/prompts.py
# 导入正则表达式模块,用于变量提取
import re
import json
from pathlib import Path
from .messages import SystemMessage, HumanMessage, AIMessage
# 定义提示词模板类
class PromptTemplate:
# 类说明文档,描述用途
"""提示词模板类,用于格式化字符串模板"""
# 构造方法,初始化模板实例
def __init__(self, template: str, partial_variables: dict = None):
# 保存模板字符串到实例属性
self.template = template
# 保存部分变量(已预填充的变量)
self.partial_variables = partial_variables or {}
# 调用内部方法提取模板中的变量名列表
all_variables = self._extract_variables(template)
# 从所有变量中排除已部分填充的变量
self.input_variables = [v for v in all_variables if v not in self.partial_variables]
# 类方法:从模板字符串生成 PromptTemplate 实例
@classmethod
def from_template(cls, template: str):
# 返回用 template 实例化的 PromptTemplate 对象
return cls(template=template)
# 格式化填充模板中的变量
def format(self, **kwargs):
# 合并部分变量和用户提供的变量
all_vars = {**self.partial_variables, **kwargs}
# 计算模板中缺失但未传入的变量名集合
missing_vars = set(self.input_variables) - set(kwargs.keys())
# 如果存在缺失变量则抛出异常,提示哪些变量缺失
if missing_vars:
raise ValueError(f"缺少必需的变量: {missing_vars}")
# 使用传入参数填充模板并返回格式化后的字符串
return self.template.format(**all_vars)
# 内部方法:从模板字符串中提取变量名
def _extract_variables(self, template: str):
# 定义正则表达式,匹配花括号中的变量名(冒号前的部分)
pattern = r'\{([^}:]+)(?::[^}]+)?\}'
# 查找所有符合 pattern 的变量名,返回匹配结果列表
matches = re.findall(pattern, template)
# 利用 dict 去重并保持顺序,最后转为列表返回
return list(dict.fromkeys(matches))
# 定义部分填充模板变量的方法,返回新的模板实例
def partial(self, **kwargs):
"""
部分填充模板变量,返回一个新的 PromptTemplate 实例
Args:
**kwargs: 要部分填充的变量及其值
Returns:
新的 PromptTemplate 实例,其中指定的变量已被填充
示例:
template = PromptTemplate.from_template("你好,我叫{name},我来自{city}")
partial_template = template.partial(name="张三")
# 现在只需要提供 city 参数
result = partial_template.format(city="北京")
"""
# 合并现有对象的部分变量(partial_variables)和本次要填充的新变量
new_partial_variables = {**self.partial_variables, **kwargs}
# 使用原模板字符串和更新后的部分变量,创建新的 PromptTemplate 实例
new_template = PromptTemplate(
template=self.template,
partial_variables=new_partial_variables
)
# 返回新的 PromptTemplate 实例
return new_template
# 定义一个用于存放格式化后的消息的类
class ChatPromptValue:
# 聊天提示词值类,包含格式化后的消息列表
"""聊天提示词值类,包含格式化后的消息列表"""
# 构造函数,接收一个消息对象列表
def __init__(self, messages):
# 保存消息列表到实例变量
self.messages = messages
# 将消息对象列表转为字符串,方便展示
def to_string(self):
# 新建一个用于存放字符串的列表
parts = []
# 遍历每个消息对象
for msg in self.messages:
# 如果消息对象有type和content属性
if hasattr(msg, 'type') and hasattr(msg, 'content'):
# 定义消息角色的映射关系
role_map = {
"system": "System",
"human": "Human",
"ai": "AI"
}
# 获取对应的角色字符串,没有则首字母大写
role = role_map.get(msg.type, msg.type.capitalize())
# 拼接角色和消息内容
parts.append(f"{role}: {msg.content}")
else:
# 如果不是标准消息对象,则直接转为字符串
parts.append(str(msg))
# 将所有消息用换行符拼接起来组成一个字符串
return "\n".join(parts)
# 返回消息对象列表本身
def to_messages(self):
# 直接返回消息列表
return self.messages
# 定义用于处理多轮对话消息模板的类
class ChatPromptTemplate:
# 聊天提示词模板类,用于创建多轮对话的提示词
"""聊天提示词模板类,用于创建多轮对话的提示词"""
# 构造方法,接收一个消息模板/对象的列表
def __init__(self, messages):
# 保存消息模板/对象列表
self.messages = messages
# 提取所有输入变量并存入实例变量
self.input_variables = self._extract_input_variables()
# 定义一个类方法,用于通过消息对象列表创建 ChatPromptTemplate 实例
@classmethod
def from_messages(cls, messages):
# 使用传入的 messages 参数创建并返回 ChatPromptTemplate 实例
return cls(messages=messages)
# 使用提供的变量格式化模板,返回消息列表
def format_messages(self, **kwargs):
# 格式化所有消息并返回
return self._format_all_messages(kwargs)
# 私有方法,提取所有模板中用到的输入变量名
def _extract_input_variables(self):
# 用集合保存变量名,防止重复
variables = set()
# 遍历所有消息模板/对象
for msg in self.messages:
# 如果元素是(role, template_str)元组
if isinstance(msg, tuple) and len(msg) == 2:
_, template_str = msg
# 用PromptTemplate对象提取变量
prompt = PromptTemplate.from_template(template_str)
# 合并到集合中
variables.update(prompt.input_variables)
# 如果是BaseMessagePromptTemplate子类实例
elif isinstance(msg, BaseMessagePromptTemplate):
variables.update(msg.prompt.input_variables)
# 如果是占位符对象
elif isinstance(msg, MessagesPlaceholder):
variables.add(msg.variable_name)
# 返回所有变量名组成的列表
return list(variables)
# 根据输入变量格式化所有消息模板,返回ChatPromptValue对象
def invoke(self, input_variables):
# 对消息模板进行实际变量填充
formatted_messages = self._format_all_messages(input_variables)
# 封装成ChatPromptValue对象返回
return ChatPromptValue(messages=formatted_messages)
# 将所有消息模板格式化并转换为消息对象列表
def _format_all_messages(self, variables):
# 新建列表保存格式化好的消息
formatted_messages = []
# 遍历每一个消息模板/对象
for msg in self.messages:
# 若是(role, template_str)元组
if isinstance(msg, tuple) and len(msg) == 2:
role, template_str = msg
# 创建PromptTemplate模板并填充变量
prompt = PromptTemplate.from_template(template_str)
content = prompt.format(**variables)
# 根据角色字符串生成对应的消息对象
formatted_messages.append(self._create_message_from_role(role, content))
# 如果是BaseMessagePromptTemplate的实例
elif isinstance(msg, BaseMessagePromptTemplate):
# 调用BaseMessagePromptTemplate的format方法,返回消息对象
formatted_messages.append(msg.format(**variables))
# 如果是占位符对象
elif isinstance(msg, MessagesPlaceholder):
placeholder_messages = self._coerce_placeholder_value(
msg.variable_name, variables.get(msg.variable_name)
)
formatted_messages.extend(placeholder_messages)
else:
# 如不是模板,直接加入
formatted_messages.append(msg)
# 返回所有格式化的消息对象列表
return formatted_messages
# 处理占位符对象的值,返回消息对象列表
def _coerce_placeholder_value(self, variable_name, value):
# 如果未传入变量,抛出异常
if value is None:
raise ValueError(f"MessagesPlaceholder '{variable_name}' 对应变量缺失")
# 如果是ChatPromptValue实例,转换为消息列表
if isinstance(value, ChatPromptValue):
return value.to_messages()
# 如果已经是消息对象/结构列表,则依次转换
if isinstance(value, list):
return [self._coerce_single_message(item) for item in value]
# 其他情况尝试单个转换
return [self._coerce_single_message(value)]
# 单个原始值转换为消息对象
def _coerce_single_message(self, value):
# 已是有效消息类型,直接返回
if isinstance(value, (SystemMessage, HumanMessage, AIMessage)):
return value
# 有type和content属性,也当消息对象直接返回
if hasattr(value, "type") and hasattr(value, "content"):
return value
# 字符串变为人类消息
if isinstance(value, str):
return HumanMessage(content=value)
# (role, content)元组转为指定角色的消息
if isinstance(value, tuple) and len(value) == 2:
# 解包元组
role, content = value
# 根据role和content生成对应的消息对象
return self._create_message_from_role(role, content)
# 字典,默认user角色
if isinstance(value, dict):
# 获取role和content
role = value.get("role", "user")
# 获取content
content = value.get("content", "")
# 根据role和content生成对应的消息对象
return self._create_message_from_role(role, content)
# 其他无法识别类型,抛出异常
raise TypeError("无法将占位符内容转换为消息")
# 辅助方法:根据角色和内容生成对应的标准消息对象
def _create_message_from_role(self, role, content):
# 角色字符串转小写做归一化
normalized_role = role.lower()
# 如果是system角色,返回SystemMessage对象
if normalized_role == "system":
return SystemMessage(content=content)
# 如果是human或user角色,返回HumanMessage对象
if normalized_role in ("human", "user"):
return HumanMessage(content=content)
# 如果是ai或assistant角色,返回AIMessage对象
if normalized_role in ("ai", "assistant"):
return AIMessage(content=content)
# 如果角色未知,则抛出异常
raise ValueError(f"未知的消息角色: {role}")
# 定义基础消息提示词模板类
class BaseMessagePromptTemplate:
# 基础消息提示词模板类声明
"""基础消息提示词模板类"""
# 构造函数,必须传入PromptTemplate实例
def __init__(self, prompt: PromptTemplate):
# 将PromptTemplate实例保存在self.prompt属性中
self.prompt = prompt
# 工厂方法,利用模板字符串创建类实例
@classmethod
def from_template(cls, template: str):
# 通过模板字符串创建PromptTemplate对象
prompt = PromptTemplate.from_template(template)
# 用生成的PromptTemplate创建本类实例并返回
return cls(prompt=prompt)
# 格式化当前模板,返回消息对象
def format(self, **kwargs):
# 使用PromptTemplate格式化内容,得到最终文本
content = self.prompt.format(**kwargs)
# 调用子类实现的方法将文本转换为对应类型消息对象
return self._create_message(content)
# 抽象方法,子类必须实现,用于生成特定类型的消息对象
def _create_message(self, content):
raise NotImplementedError
# 系统消息提示词模板类,继承自BaseMessagePromptTemplate
class SystemMessagePromptTemplate(BaseMessagePromptTemplate):
# 系统消息提示词模板说明
"""系统消息提示词模板"""
# 实现父类的_create_message方法,返回系统消息对象
def _create_message(self, content):
# 创建并返回SystemMessage对象,内容为content
return SystemMessage(content=content)
# 人类消息提示词模板类,继承自BaseMessagePromptTemplate
class HumanMessagePromptTemplate(BaseMessagePromptTemplate):
# 人类消息提示词模板说明
"""人类消息提示词模板"""
# 实现父类的_create_message方法,返回人类消息对象
def _create_message(self, content):
# 创建并返回HumanMessage对象,内容为content
return HumanMessage(content=content)
# AI消息提示词模板类,继承自BaseMessagePromptTemplate
class AIMessagePromptTemplate(BaseMessagePromptTemplate):
# AI消息提示词模板说明
"""AI消息提示词模板"""
# 实现父类的_create_message方法,返回AI消息对象
def _create_message(self, content):
# 创建并返回AIMessage对象,内容为content
return AIMessage(content=content)
# 定义动态消息列表占位符类
class MessagesPlaceholder:
# 在聊天模板中插入动态消息列表的占位符
"""在聊天模板中插入动态消息列表的占位符"""
# 构造方法,存储变量名
def __init__(self, variable_name: str):
self.variable_name = variable_name
# 定义 FewShotPromptTemplate 类,用于构建 few-shot 提示词模板
class FewShotPromptTemplate:
# 文档字符串:说明该类用于构造 few-shot 提示词的模板
"""用于构造 few-shot 提示词的模板"""
# 构造方法,初始化类的各种属性
def __init__(
self,
*,# 在 * 后面的所有参数,调用时必须使用关键字参数的形式,不能使用位置参数。
examples: list[dict] = None, # 示例列表,元素为字典类型
example_prompt: PromptTemplate | str, # 示例模板,可以是 PromptTemplate 对象或字符串
prefix: str = "", # few-shot 提示词的前缀内容
suffix: str = "", # few-shot 提示词的后缀内容
example_separator: str = "\n\n", # 每个示例之间用的分隔符
+ example_selector=None, # 示例选择器(可选)
):
# 如果提供了示例选择器,则使用选择器;否则使用提供的示例列表
+ self.example_selector = example_selector
# 如果未传入 examples,默认使用空列表
self.examples = examples or []
# 判断 example_prompt 是否为 PromptTemplate 类型
if isinstance(example_prompt, PromptTemplate):
# 如果是 PromptTemplate,直接赋值
self.example_prompt = example_prompt
else:
# 如果是字符串,则先用 from_template 创建 PromptTemplate 再赋值
self.example_prompt = PromptTemplate.from_template(example_prompt)
# 保存前缀内容
self.prefix = prefix
# 保存后缀内容
self.suffix = suffix
# 保存示例分隔符
self.example_separator = example_separator
# 如果未指定输入变量,则自动根据前后缀推断变量名
+ self.input_variables = self._infer_input_variables()
# 私有方法:推断前缀和后缀出现的模板变量名
def _infer_input_variables(self) -> list[str]:
# 新建一个集合用于保存变量名(去重)
variables = set()
# 提取 prefix 中引用的变量名
variables.update(self._extract_vars(self.prefix))
# 提取 suffix 中引用的变量名
variables.update(self._extract_vars(self.suffix))
# 转换为列表返回
return list(variables)
# 私有方法:提取文本中所有花括号包裹的模板变量名
def _extract_vars(self, text: str) -> list[str]:
# 如果输入为空字符串,直接返回空列表
if not text:
return []
# 定义正则表达式,匹配 {变量名} 或 {变量名:格式}
pattern = r"\{([^}:]+)(?::[^}]+)?\}"
# 使用 re.findall 提取所有变量名
matches = re.findall(pattern, text)
# 去重并保持顺序返回变量名列表
return list(dict.fromkeys(matches))
# 格式化 few-shot 提示词,返回完整字符串
def format(self, **kwargs) -> str:
"""
根据传入的变量生成完整的 few-shot 提示词文本
Args:
**kwargs: 输入变量,可选,供示例选择
"""
# 判断必需的变量是否全部传入,缺失时抛异常
missing = set(self.input_variables) - set(kwargs.keys())
if missing:
raise ValueError(f"缺少必需的变量: {missing}")
# 新建 parts 列表,用于拼接完整提示词的各部分内容
parts: list[str] = []
# 如果前缀不为空,格式化后加入 parts
if self.prefix:
parts.append(self._format_text(self.prefix, **kwargs))
# 格式化所有示例并拼接为块
# 如果使用示例选择器,传递输入变量;否则不传递
+ if self.example_selector:
+ example_block = self.example_separator.join(self.format_examples(input_variables=kwargs))
+ else:
+ example_block = self.example_separator.join(self.format_examples())
# 如果 example_block 不为空字符串,加入 parts
if example_block:
parts.append(example_block)
# 如果后缀不为空,格式化后加入 parts
if self.suffix:
parts.append(self._format_text(self.suffix, **kwargs))
# 用示例分隔符连接所有组成部分,过滤空字符串
return self.example_separator.join(part for part in parts if part)
# 格式化所有示例,返回字符串列表
def format_examples(self, input_variables: dict = None) -> list[str]:
"""
返回格式化后的示例字符串列表
Args:
input_variables: 输入变量字典(预留,将来可以用于定制每个示例的选择)
"""
# 如果提供了示例选择器,使用选择器选择示例
+ if self.example_selector:
+ selected_examples = self.example_selector.select_examples(input_variables)
+ else:
+ selected_examples = self.examples
# 新建存放格式化后示例的列表
formatted = []
# 遍历 every example 字典
+ for example in selected_examples:
# 用 example_prompt 对当前示例格式化
formatted.append(self.example_prompt.format(**example))
# 返回格式化后的所有示例字符串列表
return formatted
# 私有方法:用 PromptTemplate 对 text 进行格式化
def _format_text(self, text: str, **kwargs) -> str:
# 先创建 PromptTemplate 实例
temp_prompt = PromptTemplate.from_template(text)
# 用传入参数格式化
return temp_prompt.format(**kwargs)
# 定义一个从文件加载提示词模板的函数
def load_prompt(path: str | Path, encoding: str | None = None) -> PromptTemplate:
# 将传入的路径参数转换为 Path 对象,方便后续进行文件操作
file_path = Path(path)
# 判断文件是否存在,如果不存在则抛出 FileNotFoundError 异常
if not file_path.exists():
raise FileNotFoundError(f"提示词文件不存在: {path}")
# 判断文件扩展名是否为 .json,如果不是则抛出 ValueError 异常
if file_path.suffix != ".json":
raise ValueError(f"只支持 .json 格式文件,当前文件: {file_path.suffix}")
# 打开文件,使用指定编码(一般为 utf-8),并读取 JSON 配置信息到 config 变量
with file_path.open(encoding=encoding) as f:
config = json.load(f)
# 从配置字典中获取 "_type" 字段,不存在则默认值为 "prompt"
config_type = config.get("_type", "prompt")
# 校验 _type 字段是否为 "prompt",如果不是则抛出异常
if config_type != "prompt":
raise ValueError(f"不支持的提示词类型: {config_type},当前只支持 'prompt'")
# 从配置中获取模板字符串 template,如果不存在则抛出异常
template = config.get("template")
if template is None:
raise ValueError("配置文件中缺少 'template' 字段")
# 使用读取到的模板字符串创建 PromptTemplate 实例并返回
return PromptTemplate.from_template(template)12.4 类 #
12.4.1 类说明 #
| 类名 | 主要功能 | 主要方法/属性 |
|---|---|---|
| ChatOpenAI | 封装与 OpenAI 聊天模型的交互,用于调用大语言模型生成回复 | • __init__(model, **kwargs) - 初始化,指定模型名称• invoke(input, **kwargs) - 调用模型生成回复,返回 AIMessage• model - 模型名称属性• _convert_input(input) - 私有方法,将输入转换为 API 需要的消息格式 |
| PromptTemplate | 提示词模板类,用于格式化字符串模板,支持变量替换 | • __init__(template, partial_variables) - 初始化模板实例• from_template(template) - 类方法,从模板字符串创建实例• format(**kwargs) - 格式化填充模板中的变量,返回字符串• template - 模板字符串属性• input_variables - 输入变量列表属性• _extract_variables(template) - 私有方法,提取模板中的变量名 |
| FewShotPromptTemplate | Few-shot 提示词模板类,用于构建包含示例的提示词,支持使用示例选择器动态选择示例 | • __init__(examples, example_prompt, prefix, suffix, example_separator, example_selector) - 初始化,可接收示例选择器• format(**kwargs) - 格式化 few-shot 提示词,返回完整字符串• format_examples(input_variables) - 格式化所有示例,返回字符串列表• examples - 示例列表属性• example_prompt - 示例模板属性(PromptTemplate)• example_selector - 示例选择器属性(可选)• prefix - 前缀内容属性• suffix - 后缀内容属性• example_separator - 示例分隔符属性• input_variables - 输入变量列表属性• _infer_input_variables() - 私有方法,从前后缀推断输入变量• _format_text(text, **kwargs) - 私有方法,格式化文本 |
| LengthBasedExampleSelector | 基于长度的示例选择器,根据输入长度自动选择合适数量的示例,确保总长度不超过限制 | • __init__(examples, example_prompt, max_length, get_text_length) - 初始化,接收示例列表、示例模板、最大长度等• select_examples(input_variables) - 根据输入长度选择示例,返回选中的示例列表• examples - 示例列表属性• example_prompt - 示范模板属性(PromptTemplate)• max_length - 最大长度属性(默认 2048)• get_text_length - 文本长度计算函数属性• example_text_lengths - 示例长度列表属性(缓存)• _default_get_text_length(text) - 私有方法,默认长度计算(按单词数)• _calculate_example_lengths() - 私有方法,计算所有示例的长度 |
| BaseExampleSelector | 示例选择器的抽象基类,定义了选择器的接口规范(间接使用) | • select_examples(input_variables) - 抽象方法,子类必须实现• 作为 LengthBasedExampleSelector 的基类 |
| AIMessage | AI 消息类,表示 AI 助手的回复消息(间接使用) | • __init__(content, **kwargs) - 初始化,type 固定为"ai"• content - 消息内容属性• type - 消息类型属性(值为"ai") |
12.4.2 类关系图 #
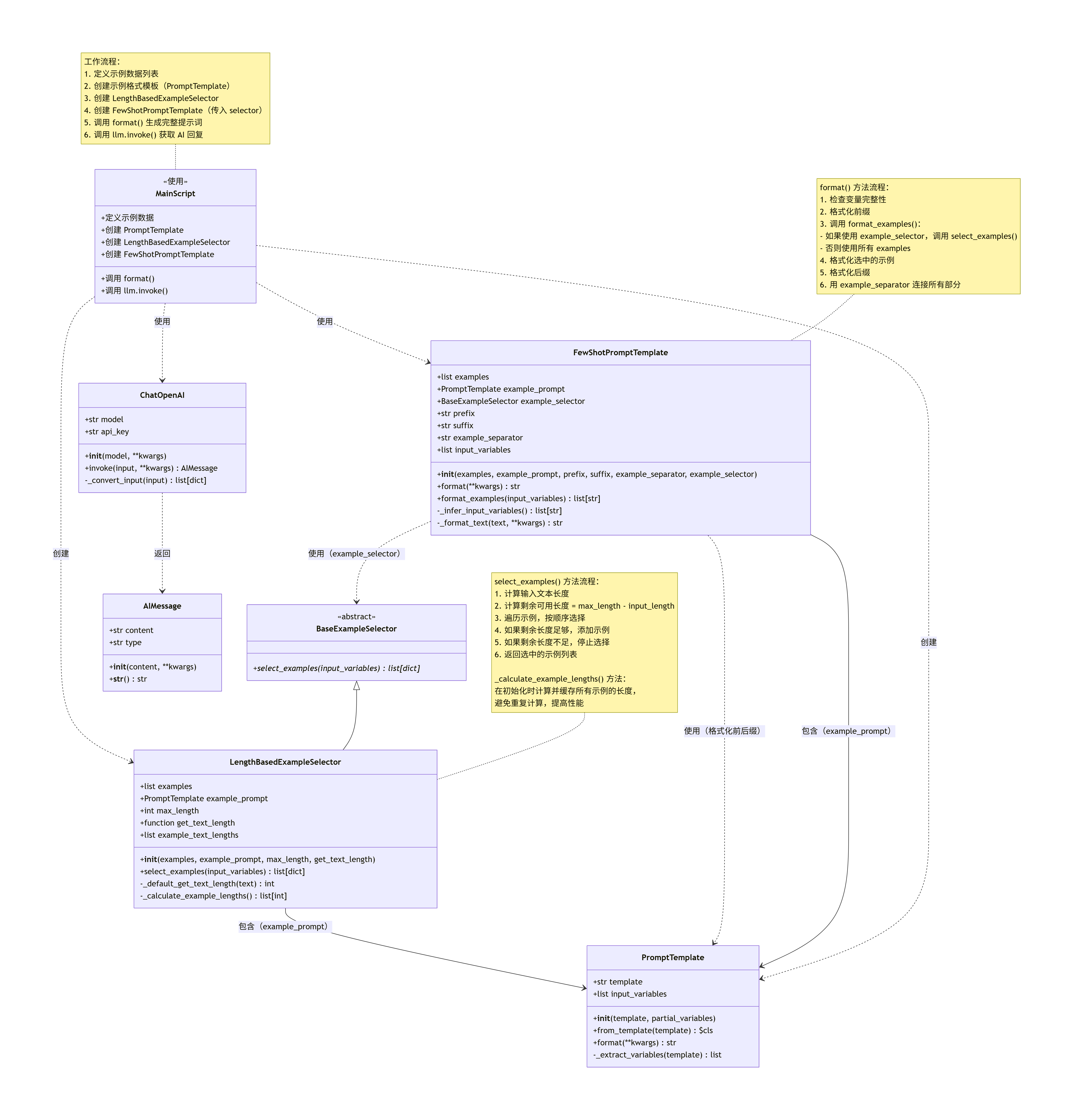
12.4.3 调用关系图 #
12.4.4 数据流转 #
示例数据定义
- 创建示例字典列表,每个字典包含问题和答案
- 示例:
[{"question": "1 plus 1等于多少?", "answer": "答案是2"}, ...]
示例模板创建
- 使用
PromptTemplate.from_template()创建示例格式模板 - 定义每个示例的显示格式:
"问题:{question}\n答案:{answer}"
- 使用
示例选择器创建
- 使用
LengthBasedExampleSelector创建选择器 - 初始化时:
- 保存示例列表和示例模板
- 调用
_calculate_example_lengths()计算并缓存所有示例的长度 - 设置最大长度限制(
max_length=15)
- 使用
Few-shot 模板创建
- 使用
FewShotPromptTemplate创建模板 - 传入
example_selector参数,而不是直接传入examples - 自动从前后缀推断输入变量:
["user_question"]
- 使用
模板格式化
- 调用
few_shot_prompt.format(user_question="...") - 处理流程:
- 格式化前缀
- 调用
format_examples(input_variables=kwargs) - 在
format_examples()中:- 调用
example_selector.select_examples(input_variables) - 选择器计算输入长度,根据剩余长度选择示例
- 返回选中的示例列表
- 调用
- 格式化选中的示例
- 格式化后缀
- 组合所有部分
- 调用
示例选择逻辑
- 计算输入文本长度:
input_length = get_text_length(input_text) - 计算剩余可用长度:
remaining_length = max_length - input_length - 遍历示例,按顺序选择:
- 如果剩余长度足够,添加示例
- 如果剩余长度不足,停止选择
- 返回选中的示例列表
- 计算输入文本长度:
模型调用
- 将格式化后的提示词传给
ChatOpenAI.invoke() - 返回
AIMessage对象
- 将格式化后的提示词传给
13. MaxMarginalRelevanceExampleSelector #
在 few-shot 提示构建中,MaxMarginalRelevanceExampleSelector(最大边际相关性示例选择器,简称 MMR Selector)是一种智能范例选择机制,它可以动态从大量可用示例中筛选出“最相关且多样”的 few-shot 样例,帮助大模型高效学习并作答。
工作原理
MMR 选择器与传统静态的样例列表不同,它借助向量数据库(如 FAISS)和嵌入模型(如 OpenAIEmbeddings)实现了如下流程:
范例嵌入与索引建立
- 首次创建时,将所有候选示例转换为文本(如“问题:……\n答案:……”),再用嵌入模型转为高维向量。
- 这些向量文本对被批量加入 FAISS 向量数据库,便于后续相似检索。
动态检索与筛选
- 当构造 Prompt 需选示例时,先将当前「用户输入」转为查询向量。
- 使用向量库,先检索出 fetch_k(如 20)个和查询最相近的候选示例(用余弦相似度或 L2 距离)。
- 通过 MMR 算法,从上述候选中进一步筛出 k 个样例,使它们既与查询高度相关,又彼此差异最大,内容多样、避免冗余。
组合到 Prompt 中
- 被选中的样例按模板格式化后作为 few-shot 部分加入到前缀与用户输入之间,提升模型对具体问题的理解能力。
算法说明
- 余弦相似度(cosine_similarity):度量向量间的相似程度,值越大越相关。
- MMR 规则(mmr_select):
- 首先选与 query 最相关的一个示例。
- 之后每次从未被选中的候选集中,挑选“综合考虑与 query 的相关性和与已选样例的多样性”的那个,直到选满 k 个。
- 控制参数 lambda_mult 可调整“相关性”和“多样性”权重。
调用流程图
组件表
| 类/函数名 | 作用 | 关联参数/方法 |
|---|---|---|
PromptTemplate |
定义单条样例的格式化模板 | from_template, format |
FewShotPromptTemplate |
用 few-shot 示例组合完整 Prompt | example_selector, prefix, ... |
MaxMarginalRelevanceExampleSelector |
实现“相关且多样”的动态样例筛选 | from_examples, select_examples |
OpenAIEmbeddings |
将文本转为高维浮点向量 | embed_documents |
FAISS (向量存储) |
高效管理大批向量、支持快速最近邻与MMR检索 | from_texts, add_texts, max_marginal_relevance_search |
mmr_select(算法) |
从候选向量集合中挑出最相关且多样的 k 个 | lambda_mult, k, ... |
cosine_similarity(函数) |
计算查询与候选向量间的相似度 | from_vec, to_vecs |
Document |
封装单条文本(样例)及元信息和嵌入向量 | embedding_value, metadata |
优势
- 智能化 few-shot:不再死板挪用全部或靠人工手选 few-shot,能动态组队,模型适应性更强。
- 相关+多样:既能紧扣用户问题,又能防止示例重复/冗余,极大提升模型生成效果。
- 高效扩展:支持大规模示例库,易于管理和扩充。
13.1. 13.MaxMarginalRelevanceExampleSelector.py #
13.MaxMarginalRelevanceExampleSelector.py
#from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
#from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
#from langchain_openai import ChatOpenAI, OpenAIEmbeddings
#from langchain_community.vectorstores import FAISS
# 导入自定义的ChatOpenAI类(用于与大语言模型对话)
from smartchain.chat_models import ChatOpenAI
# 导入OpenAI的文本嵌入模型,用于将文本转换为向量
from smartchain.embeddings import OpenAIEmbeddings
# 导入提示模板PromptTemplate和FewShotPromptTemplate,用于构建few-shot提示
from smartchain.prompts import PromptTemplate, FewShotPromptTemplate
# 导入最大边际相关性(MMR)示例选择器
from smartchain.example_selectors import MaxMarginalRelevanceExampleSelector
# 导入FAISS向量数据库实现,用于向量化检索
from smartchain.vectorstores import FAISS
# 定义10个围绕“怎样挑西瓜比较甜”等类似主题的中英文QA示例组成的列表
examples = [
{"question": "如何挑选新鲜的水果?", "answer": "观察外皮是否光滑、色泽是否自然,还可以闻闻香味,挑选表皮无破损的新鲜水果。"},
{"question": "西瓜挑选时要注意什么?", "answer": "应选择西瓜纹路清晰、瓜皮发亮,敲打有清脆声音,瓜蒂卷曲、瓜底发黄的通常比较甜。"},
{"question": "西瓜怎么挑才甜?", "answer": "用手轻轻拍打西瓜,发出清脆、沉闷有弹性之音的西瓜比较甜"},
{"question": "买水果有哪些小窍门?", "answer": "挑选时需观察颜色、闻气味、用手掂分量。对于瓜类可以敲一敲听声音来判断成熟度。"},
{"question": "怎样判断水果是否熟透?", "answer": "可以轻捏表皮,成熟的水果通常较软,闻一闻是否有浓郁的水果香味,也可以看颜色是否均匀。"},
{"question": "西瓜的黄底有什么意义?", "answer": "西瓜底部颜色越黄,通常说明在田里成熟时间长,甜度更高。"},
{"question": "挑西瓜时候能用手敲吗?", "answer": "可以,声音清脆表示瓜比较熟,声音沉闷的可能不太熟。"},
{"question": "吃西瓜对健康有哪些好处?", "answer": "西瓜含有丰富水分和多种维生素,夏季吃可补水解暑,有利于身体健康。"},
{"question": "水果要怎么保存更久?", "answer": "可存放于阴凉处,易腐水果置于冰箱冷藏,有些水果如西瓜最好切块密封保存。"},
{"question": "哪些水果适合夏天吃?", "answer": "西瓜、哈密瓜、桃子、李子等含水分高的水果特别适合夏天食用。"}
]
# 创建格式化示例的模板(把每个示例按“问题+答案”格式化为字符串)
example_prompt = PromptTemplate.from_template(
"问题:{question}\n答案:{answer}"
)
# 创建OpenAI嵌入模型实例,使能将文本转成向量
embeddings = OpenAIEmbeddings()
# 利用MMR算法和FAISS,通过from_examples方法构建最大边际相关性选择器
selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples=examples, # 传入全部示例列表
embeddings=embeddings, # 指定用OpenAIEmbedding做向量化
vectorstore_cls=FAISS, # 用FAISS作为向量检索数据库
k=3, # 最终动态挑选3个最相关的few-shot示例
fetch_k=5, # 初步检索5个候选,再用MMR算法选最有代表性的3个
)
# 构建FewShotPromptTemplate,实现自动拼接few-shot样例与用户输入
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt, # 指定样例格式模板
prefix="你是一个乐于助人的生活小助手。以下是一些建议示例:", # 固定前缀开头
suffix="问题:{question}\n答案:", # 后缀接用户本次提问
example_selector=selector # few-shot样例的动态选择器为上面构建的MMR Selector
)
# 设定本次用户的真实提问
user_question = "怎样挑西瓜比较甜?"
# 用FewShotPrompt拼接few-shot样例与用户问题,生成完整的大模型输入提示词
formatted = few_shot_prompt.format(question=user_question)
# 打印输出最终的完整Prompt(包含若干示例+用户输入)
print(formatted)
# 创建ChatOpenAI对象实例,指定用gpt-4o模型进行对话
llm = ChatOpenAI(model="gpt-4o")
# 用invoke方法向GPT发送拼好的Prompt,获得模型回复
result = llm.invoke(formatted)
# 打印“AI 回复:”的引导语
print("AI 回复:")
# 打印AI输出的真正答案内容
print(result.content)13.2. embeddings.py #
smartchain/embeddings.py
# 导入os模块,用于读取环境变量
import os
# 导入OpenAI官方SDK
from openai import OpenAI
# 导入ABC和abstractmethod,用于定义抽象基类
from abc import ABC, abstractmethod
# 导入SentenceTransformer用于嵌入模型
from sentence_transformers import SentenceTransformer
# 从langchain_huggingface导入HuggingFaceEmbeddings并重命名
from langchain_huggingface import (
HuggingFaceEmbeddings as LangchainHuggingFaceEmbeddings,
)
# 导入requests库,用于发送HTTP请求
import requests
# 定义抽象基类Embedding
class Embedding(ABC):
# 定义抽象方法,嵌入单个查询文本
@abstractmethod
def embed_query(self, text):
pass
# 定义抽象方法,嵌入多个文档文本
@abstractmethod
def embed_documents(self, texts):
pass
# OpenAI 嵌入模型封装
class OpenAIEmbeddings(Embedding):
# 初始化方法,支持自定义模型和参数
def __init__(self, model="text-embedding-3-small", **kwargs):
# 模型名称
self.model = model
# 获取API密钥,优先从参数中获取,否则从环境变量中读取
self.api_key = kwargs.get("api_key") or os.getenv("OPENAI_API_KEY")
# 如果未提供api_key则报错
if not self.api_key:
raise ValueError(f"需要提供 api_key")
# 过滤掉api_key后的其他embedding参数
self.embedding_kwargs = {k: v for k, v in kwargs.items() if k != "api_key"}
# 初始化OpenAI客户端
self.client = OpenAI(api_key=self.api_key)
# 单条文本嵌入
def embed_query(self, text):
# 调用OpenAI嵌入接口,获取结果
response = self.client.embeddings.create(
model=self.model, input=text, **self.embedding_kwargs
)
# 返回第一个embedding向量
return response.data[0].embedding
# 多条文档批量嵌入
def embed_documents(self, texts):
# 调用OpenAI嵌入接口,支持批量输入
response = self.client.embeddings.create(
model=self.model, input=texts, **self.embedding_kwargs
)
# 返回所有embedding向量
return [item.embedding for item in response.data]
# HuggingFace嵌入模型封装
class HuggingFaceEmbeddings(Embedding):
# 初始化方法,支持自定义模型和其他参数
def __init__(self, model_name="sentence-transformers/all-MiniLM-L6-v2", **kwargs):
"""
初始化 HuggingFace 嵌入模型
Args:
model_name: HuggingFace 模型名称,默认为 "sentence-transformers/all-MiniLM-L6-v2"
**kwargs: 传递给 langchain_huggingface.HuggingFaceEmbeddings 的其他参数
"""
# 保存模型名称
self.model_name = model_name
# 使用langchain_huggingface库内的HuggingFaceEmbeddings进行初始化
self.embeddings = LangchainHuggingFaceEmbeddings(
model_name=model_name, **kwargs
)
# 嵌入单个查询文本
def embed_query(self, text):
"""嵌入单个查询文本"""
return self.embeddings.embed_query(text)
# 嵌入多个文档文本
def embed_documents(self, texts):
"""嵌入多个文档文本"""
return self.embeddings.embed_documents(texts)
# SentenceTransformer 嵌入模型封装
class SentenceTransformerEmbeddings(Embedding):
# 初始化方法,支持自定义模型和参数
def __init__(self, model="all-MiniLM-L6-v2", **kwargs):
"""
初始化 SentenceTransformer 嵌入模型
Args:
model: 模型名称或路径,默认为 "all-MiniLM-L6-v2"
**kwargs: 传递给 SentenceTransformer 的其他参数
"""
# 设置模型名称,若为空则用默认
self.model_name = model or "all-MiniLM-L6-v2"
# 通过SentenceTransformer初始化嵌入模型
self.model = SentenceTransformer(self.model_name, **kwargs)
# 是否归一化返回的向量,默认为False
self.normalize_embeddings = kwargs.get("normalize_embeddings", False)
# 嵌入单个文本
def embed_query(self, text):
"""嵌入单个查询文本"""
# 使用模型进行编码,支持归一化
embedding = self.model.encode(
text, normalize_embeddings=self.normalize_embeddings
)
# 如果embedding有tolist方法则转为list返回,否则直接返回
return embedding.tolist() if hasattr(embedding, "tolist") else embedding
# 嵌入多个文档文本(批量)
def embed_documents(self, texts):
"""嵌入多个文档文本(批量处理以提高效率)"""
# 如果只传入了一个字符串,则转为列表
if isinstance(texts, str):
texts = [texts]
# 使用模型进行批量编码
embeddings = self.model.encode(
texts, normalize_embeddings=self.normalize_embeddings
)
# 如果返回的结果可以转为list,则转为list
if hasattr(embeddings, "tolist"):
return embeddings.tolist()
# 否则直接返回
return embeddings
# 设置文本向量API的URL
VOLC_EMBEDDINGS_API_URL = "https://ark.cn-beijing.volces.com/api/v3/embeddings"
# 火山引擎嵌入API通用函数
def get_volc_embedding(
doc_content, model="doubao-embedding-text-240715", api_key=None, api_url=None
):
"""
获取火山引擎文档向量
Args:
doc_content: 文档内容(字符串或字符串列表)
model: 模型名称,默认为 "doubao-embedding-text-240715"
api_key: API密钥,如果未提供则从环境变量 VOLC_API_KEY 获取
api_url: API地址,如果未提供则使用默认地址
Returns:
嵌入向量(单个文本返回向量,多个文本返回向量列表)
"""
# 若未显示传递API key,则从环境变量获取
if api_key is None:
api_key = os.getenv("VOLC_API_KEY")
# 如果仍未获取到api_key,则抛出异常
if not api_key:
raise ValueError("需要提供 api_key 或设置环境变量 VOLC_API_KEY")
# 若未指定api_url,则用默认URL
api_url = api_url or VOLC_EMBEDDINGS_API_URL
# 构造POST请求头,包含授权信息
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
# 构造POST请求的载体
payload = {"model": model, "input": doc_content}
# 尝试请求API
try:
# 发送POST请求,请求火山引擎embeddings API
response = requests.post(api_url, json=payload, headers=headers, timeout=30)
# 检查响应状态码,非200抛出异常
response.raise_for_status() # 如果状态码不是 200,会抛出异常
# 解析JSON响应内容
data = response.json()
# 判断输入是单个还是多个
if isinstance(doc_content, list):
# 多条输入,返回所有向量组成的列表
return [item["embedding"] for item in data.get("data", [])]
else:
# 单条输入,返回第一个embedding向量
return data["data"][0]["embedding"]
# 捕获网络请求相关异常
except requests.exceptions.RequestException as e:
raise Exception(f"火山引擎 Embedding API 请求失败: {str(e)}")
# 捕获响应结构异常
except (KeyError, IndexError) as e:
raise Exception(f"火山引擎 Embedding API 响应格式错误: {str(e)}")
# 封装火山引擎嵌入模型类
class VOLCEmbeddings(Embedding):
# 初始化方法,支持自定义模型、API key、API地址及其他参数
def __init__(
self, model="doubao-embedding-text-240715", api_key=None, api_url=None, **kwargs
):
"""
初始化火山引擎嵌入模型
Args:
model: 模型名称,默认为 "doubao-embedding-text-240715"
api_key: API密钥,如果未提供则从环境变量 VOLC_API_KEY 获取
api_url: API地址,如果未提供则使用默认地址
**kwargs: 其他参数(保留用于未来扩展)
"""
# 模型名称
self.model = model
# API密钥优先参数,其次环境变量
self.api_key = api_key or os.getenv("VOLC_API_KEY")
# 未获取到api_key抛异常
if not self.api_key:
raise ValueError("需要提供 api_key 或设置环境变量 VOLC_API_KEY")
# API地址
self.api_url = api_url or VOLC_EMBEDDINGS_API_URL
# 其他embedding相关参数
self.embedding_kwargs = kwargs
# 嵌入单条文本
def embed_query(self, text):
"""嵌入单个查询文本"""
# 调用火山引擎API,返回向量
return get_volc_embedding(
text, model=self.model, api_key=self.api_key, api_url=self.api_url
)
# 嵌入多条文本
def embed_documents(self, texts):
"""嵌入多个文档文本"""
# 如果输入是单条字符串,则转为列表
if isinstance(texts, str):
texts = [texts]
# 批量嵌入,提高效率
return get_volc_embedding(
texts, model=self.model, api_key=self.api_key, api_url=self.api_url
)
13.3. vectorstores.py #
smartchain/vectorstores.py
# 导入os模块
import os
# 导入numpy用于数值计算
import numpy as np
# 导入抽象基类相关模块
from abc import ABC, abstractmethod
# 导入faiss库用于向量检索
import faiss
# 定义余弦相似度计算函数
def cosine_similarity(from_vec, to_vecs):
"""
计算一个向量与多个向量的余弦相似度
参数:
from_vec: 单个向量(1D或2D数组或列表)
to_vecs: 多个向量(2D或3D数组,每一行为一个向量)
返回:
一维数组,包含单个向量与每个多个向量的相似度
示例:
sims = cosine_similarity(from_vec, to_vecs)
"""
# 将from_vec转换为NumPy数组并设置为float类型
from_vec = np.array(from_vec, dtype=float)
# 将to_vecs转换为NumPy数组并设置为float类型
to_vecs = np.array(to_vecs, dtype=float)
# 计算from_vec的范数
norm1 = np.linalg.norm(from_vec)
# 如果from_vec为零向量,直接返回全0相似度数组
if norm1 == 0:
return np.zeros(len(to_vecs))
# 初始化相似度结果列表
similarities = []
# 遍历每一个目标向量to_vec
for to_vec in to_vecs:
# 计算from_vec和to_vec的点积
dot_product = np.sum(from_vec * to_vec)
# 计算to_vec的范数
norm_vec = np.linalg.norm(to_vec)
# 如果to_vec为零向量,相似度记为0
if norm_vec == 0:
similarities.append(0.0)
else:
# 计算余弦相似度
similarity = dot_product / (norm1 * norm_vec)
similarities.append(similarity)
# 返回相似度结果的NumPy数组
return np.array(similarities)
# 定义最大边际相关性(MMR)算法函数
def mmr_select(query_vector, doc_vectors, k=3, lambda_mult=0.5):
"""
使用最大边际相关性(MMR)算法选择文档
参数:
query_vector: 查询向量(1D数组)
doc_vectors: 文档向量集合(2D数组,每行一个文档向量)
k: 要选择的文档数量(默认3)
lambda_mult: λ参数,平衡相关性与多样性(默认0.5)
- λ=1: 只看相关性
- λ=0: 只看多样性
- λ=0.5: 平衡相关性和多样性
返回:
selected: 选中的文档索引列表(从0开始)
示例:
selected = mmr_select(query_vector, doc_vectors, k=3, lambda_mult=0.5)
"""
# 计算所有文档与查询向量的余弦相似度
query_similarities = cosine_similarity(query_vector, doc_vectors)
# 打印每个文档与查询的相关性分数
print("文档与查询的相关性分数:")
for i, sim in enumerate(query_similarities):
# 打印文档编号及对应相似度
print(f"文档{i+1}: {sim:.4f}")
# 选中相关性最高的文档索引,作为第一个已选文档
selected = [int(np.argmax(query_similarities))]
# 直到已选择k个文档之前循环
while len(selected) < k:
# 初始化MMR分数列表
mmr_scores = []
# 遍历所有文档索引
for i in range(len(doc_vectors)):
# 如果该文档还未被选中
if i not in selected:
# 当前文档与查询的相关性分数
relevance = query_similarities[i]
# 获取已选文档的向量集合
selected_vecs = doc_vectors[selected]
# 计算当前文档与已选各文档的余弦相似度
sims = cosine_similarity(doc_vectors[i], selected_vecs)
# 获取与已选文档中最大相似度(最不多样的)
max_sim = np.max(sims)
# 按MMR公式计算分数
mmr_score = lambda_mult * relevance - (1 - lambda_mult) * max_sim
# 记录文档编号和对应的MMR分数
mmr_scores.append((i, mmr_score))
# 如果没有可选文档就跳出循环
if not mmr_scores:
break
# 选取MMR分数最高的文档编号
best_idx, best_score = max(mmr_scores, key=lambda x: x[1])
# 将该文档编号加入已选列表
selected.append(best_idx)
# 返回已选中文档的索引
return selected
# 定义Document文档对象类
class Document:
# 文档类,存储内容、元数据和嵌入向量
def __init__(self, page_content: str, metadata=None, embedding_value=None):
# 初始化文档内容
self.page_content = page_content
# 初始化元数据,默认空字典
self.metadata = metadata or {}
# 初始化嵌入向量
self.embedding_value = embedding_value
# 定义向量存储抽象基类
class VectorStore(ABC):
# 向量存储抽象基类
# 抽象方法,添加文本到向量存储
@abstractmethod
def add_texts(
self,
texts,
metadatas=None
):
# 添加文本方法为抽象方法,由子类实现
pass
# 抽象方法,最大边际相关性检索
@abstractmethod
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20
):
# 最大边际相关性检索方法为抽象方法,由子类实现
pass
# 抽象类方法,从文本批量构造向量存储
@classmethod
@abstractmethod
def from_texts(
cls,
texts,
embeddings,
metadatas=None
):
# 批量通过文本构建向量存储的抽象方法,由子类实现
pass
# 定义FAISS向量存储类,继承自VectorStore
class FAISS(VectorStore):
# FAISS向量存储实现
def __init__(
self,
embeddings, # 嵌入模型
):
# 保存嵌入模型
self.embeddings = embeddings
# 初始化FAISS索引为空
self.index = None
# 初始化文档字典,键为文档id,值为Document对象
self.documents_by_id = {}
# 添加文本到向量存储
def add_texts(
self,
texts,
metadatas=None
):
# 如果未传入元数据,则使用空字典列表
if metadatas is None:
metadatas = [{}] * len(texts)
# 利用嵌入模型生成文本的嵌入向量
embedding_values = self.embedding.embed_documents(texts)
# 转换成float32类型的NumPy数组
embedding_values = np.array(embedding_values, dtype=np.float32)
# 若还未建立FAISS索引,则新建之
if self.index is None:
dimension = len(embedding_values[0])
self.index = faiss.IndexFlatL2(dimension)
# 添加嵌入向量到FAISS索引
self.index.add(embedding_values)
# 获取当前已有文档数量,用于新文档编号
start_idx = len(self.documents_by_id)
# 遍历插入的每组文本、元数据、嵌入向量
for i, (text, metadata, embedding_value) in enumerate(zip(texts, metadatas, embedding_values)):
# 构造文档id
doc_id = str(start_idx + i)
# 构造Document对象
doc = Document(page_content=text, metadata=metadata, embedding_values=embedding_values)
# 保存进字典
self.documents_by_id[doc_id] = doc
# 最大边际相关性检索方法
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
):
# 获取查询文本的嵌入向量
query_embedding = self.embedding.embed_query(query)
# 转为二维NumPy数组
query_vector = np.array([query_embedding], dtype=np.float32) # (1, dimension)
# 用FAISS索引检索出fetch_k个候选文档(距离最近)
if isinstance(self.index, faiss.Index):
# 执行检索,返回索引及距离
_, indices = self.index.search(query_vector, fetch_k)
# 解析获得候选文档的索引列表
candidate_indices = indices[0]
else:
# 非法索引则抛出异常
raise RuntimeError("FAISS index is not available.")
# 如果候选文档不足k个,直接返回这些文档
if len(candidate_indices) <= k:
docs = []
for idx in candidate_indices:
doc_id = str(idx)
# 存在于字典才添加
if doc_id in self.documents_by_id:
docs.append(self.documents_by_id[doc_id])
return docs
# 从字典中提取候选文档的嵌入向量
candidate_vectors = np.array([self.documents_by_id[str(i)].embedding_value for i in candidate_indices], dtype=np.float32)
# 通过mmr_select获取MMR选出的下标
selected_indices = mmr_select(query_embedding, candidate_vectors, k=k, lambda_mult=lambda_mult)
# 根据选出下标获得最终文档对象
docs = []
for idx in selected_indices:
doc_id = str(candidate_indices[idx])
if doc_id in self.documents_by_id:
docs.append(self.documents_by_id[doc_id])
return docs
# 类方法:通过文本批量创建FAISS向量存储实例
@classmethod
def from_texts(
cls,
texts,
embeddings,
metadatas=None
):
# 创建FAISS实例
instance = cls(embeddings=embeddings)
# 添加全部文本及元数据
instance.add_texts(texts=texts, metadatas=metadatas)
# 返回构建好的实例
return instance13.4. example_selectors.py #
smartchain/example_selectors.py
from abc import ABC, abstractmethod
+from typing import List
from .prompts import PromptTemplate
import re
+from .vectorstores import VectorStore
# 定义示例选择器的抽象基类
class BaseExampleSelector(ABC):
"""示例选择器的抽象基类"""
@abstractmethod
def select_examples(self, input_variables: dict) -> list[dict]:
"""根据输入变量选择示例"""
pass
# 定义一个基于长度的示例选择器类
class LengthBasedExampleSelector(BaseExampleSelector):
"""
基于长度的示例选择器
根据输入长度自动选择合适数量的示例,确保总长度不超过限制
"""
# 构造方法,初始化LengthBasedExampleSelector对象
def __init__(
self,
examples: list[dict], # 示例列表,每个元素为字典
example_prompt: PromptTemplate | str, # 用于格式化示例的模板,可以是PromptTemplate或字符串
max_length: int = 2048, # 提示词最大长度,默认为2048
get_text_length=None, # 可选的文本长度计算函数
):
"""
初始化 LengthBasedExampleSelector
Args:
examples: 示例列表,每个示例是一个字典
example_prompt: 用于格式化示例的模板(PromptTemplate 或字符串)
max_length: 提示词的最大长度(默认 2048)
get_text_length: 计算文本长度的函数(默认按单词数计算)
"""
# 保存所有示例到实例变量
self.examples = examples
# 如果example_prompt是字符串,则构建为PromptTemplate对象
if isinstance(example_prompt, str):
self.example_prompt = PromptTemplate.from_template(example_prompt)
# 如果已是PromptTemplate则直接赋值
else:
self.example_prompt = example_prompt
# 保存最大长度参数
self.max_length = max_length
# 设置文本长度计算函数,默认为内部定义的按单词数计算
self.get_text_length = get_text_length or self._default_get_text_length
# 计算并缓存每个示例(格式化后)的长度
self.example_text_lengths = self._calculate_example_lengths()
# 默认的长度计算方法,统计文本中的单词数
def _default_get_text_length(self, text: str) -> int:
"""
默认的长度计算函数:按单词数计算
Args:
text: 文本内容
Returns:
文本长度(单词数)
"""
# 利用正则按空白字符分割,统计词数
return len(re.split(r'\s+', text.strip()))
# 计算所有示例格式化后的长度
def _calculate_example_lengths(self) -> list[int]:
"""
计算所有示例的长度
Returns:
每个示例的长度列表
"""
# 初始化长度列表
lengths = []
# 对每个示例进行格式化并计算长度
for example in self.examples:
# 用模板对示例内容进行格式化
formatted_example = self.example_prompt.format(**example)
# 计算格式化后示例的长度
length = self.get_text_length(formatted_example)
# 记录到列表中
lengths.append(length)
# 返回长度列表
return lengths
# 根据输入内容长度,选择合适的示例列表
def select_examples(self, input_variables: dict) -> list[dict]:
"""
根据输入长度选择示例
Args:
input_variables: 输入变量字典
Returns:
选中的示例列表
"""
# 将输入的所有变量拼成一个字符串
input_text = " ".join(str(v) for v in input_variables.values())
# 计算输入内容的长度
input_length = self.get_text_length(input_text)
# 计算剩余可用长度
remaining_length = self.max_length - input_length
# 初始化选中的示例列表
selected_examples = []
# 遍历所有示例
for i, example in enumerate(self.examples):
# 如果剩余长度已经不足,提前停止选择
if remaining_length <= 0:
break
# 获取当前示例的长度
example_length = self.example_text_lengths[i]
# 判断如果再添加这个示例会超过剩余长度,则停止选择
if remaining_length - example_length < 0:
break
# 把当前示例加入已选择列表
selected_examples.append(example)
# 更新剩余可用长度
remaining_length -= example_length
# 返回最终选中的示例列表
return selected_examples
# 辅助函数:返回按字典键排序的值组成的列表
+def sorted_values(values: dict) -> list:
# 对字典的键进行排序
# 依次取出对应的值组成新列表
+ return [values[val] for val in sorted(values)]
# 定义基于向量存储的示例选择器基类
+class VectorStoreExampleSelector(BaseExampleSelector):
# 初始化方法
+ def __init__(
+ self,
+ vectorstore: VectorStore, # 向量存储实例对象
+ k: int = 4 # 需要选择的示例数量
+ ):
# 保存向量存储对象
+ self.vectorstore = vectorstore
# 保存需要选择的示例数量
+ self.k = k
# 静态方法:将示例字典转换为一个字符串
+ @staticmethod
+ def _example_to_text(example: dict) -> str:
# 按字典键排序后拼接所有值为一个字符串
+ return " ".join(sorted_values(example))
# 将文档对象列表转换为示例字典列表
+ def _documents_to_examples(self, documents):
# 遍历每个文档对象
# 提取其元数据,并转换为字典
+ examples = [dict(doc.metadata) for doc in documents]
# 返回由所有示例组成的列表
+ return examples
# 定义最大边际相关性(MMR)示例选择器类
+class MaxMarginalRelevanceExampleSelector(VectorStoreExampleSelector):
# 初始化方法
+ def __init__(
+ self,
+ vectorstore, # 向量存储对象
+ k=4, # 需要选择的最终示例数量
+ fetch_k=20, # 检索的候选示例数量
+ ):
# 调用父类构造方法初始化基本参数
+ super().__init__(
+ vectorstore=vectorstore,
+ k=k,
+ )
# 保存每次检索的候选集大小
+ self.fetch_k = fetch_k
# 根据最大边际相关性算法,选择最终示例列表
+ def select_examples(self, input_variables):
# 将输入变量转成文本查询字符串
+ query_text = self._example_to_text(input_variables)
# 调用向量存储的最大边际相关性检索方法获取候选示例文档
+ example_docs = self.vectorstore.max_marginal_relevance_search(
+ query=query_text,
+ k=self.k,
+ fetch_k=self.fetch_k
+ )
# 将文档对象列表转换为标准的示例字典并返回
+ return self._documents_to_examples(example_docs)
# 类方法:通过一组样例创建MMR示例选择器实例
+ @classmethod
+ def from_examples(
+ cls, # 当前类
+ examples, # 示例字典列表
+ embeddings, # 嵌入模型实例
+ vectorstore_cls, # 向量存储类,如FAISS
+ k=4, # 最终选择几个示例
+ fetch_k=20, # 候选集大小
+ ):
# 先将每个样例转换为字符串(用作向量数据库的文本)
+ string_examples = [
+ cls._example_to_text(eg) for eg in examples
+ ]
# 使用向量存储类批量创建并加载这些样例(text->向量)
+ vectorstore = vectorstore_cls.from_texts(
+ texts=string_examples, # 文本列表
+ embeddings=embeddings, # 嵌入模型
+ metadatas=examples # 元数据列表
+ )
# 实例化并返回当前选择器对象
+ return cls(
+ vectorstore=vectorstore, # 构建好的向量存储实例
+ k=k, # 选择示例个数
+ fetch_k=fetch_k # 候选集大小
+ )
13.5 类 #
13.5.1 类说明 #
| 类名 | 主要功能 | 主要方法/属性 |
|---|---|---|
| ChatOpenAI | 封装与 OpenAI 聊天模型的交互,用于调用大语言模型生成回复 | • __init__(model, **kwargs) - 初始化,指定模型名称• invoke(input, **kwargs) - 调用模型生成回复,返回 AIMessage• model - 模型名称属性• _convert_input(input) - 私有方法,将输入转换为 API 需要的消息格式 |
| OpenAIEmbeddings | OpenAI 嵌入模型集成,用于将文本转换为嵌入向量 | • __init__(model, **kwargs) - 初始化,指定模型名称• embed_query(text) - 将单个文本转换为嵌入向量• embed_documents(texts) - 将多个文本批量转换为嵌入向量列表• model - 模型名称属性(默认 "text-embedding-3-small")• api_key - API 密钥属性• client - OpenAI 客户端实例属性 |
| PromptTemplate | 提示词模板类,用于格式化字符串模板,支持变量替换 | • __init__(template, partial_variables) - 初始化模板实例• from_template(template) - 类方法,从模板字符串创建实例• format(**kwargs) - 格式化填充模板中的变量,返回字符串• template - 模板字符串属性• input_variables - 输入变量列表属性 |
| FewShotPromptTemplate | Few-shot 提示词模板类,用于构建包含示例的提示词,支持使用示例选择器动态选择示例 | • __init__(examples, example_prompt, prefix, suffix, example_separator, example_selector) - 初始化,可接收示例选择器• format(**kwargs) - 格式化 few-shot 提示词,返回完整字符串• format_examples(input_variables) - 格式化所有示例,返回字符串列表• example_selector - 示例选择器属性(可选)• example_prompt - 示例模板属性• prefix - 前缀内容属性• suffix - 后缀内容属性 |
| MaxMarginalRelevanceExampleSelector | 最大边际相关性(MMR)示例选择器,基于向量相似度和多样性选择示例 | • __init__(vectorstore, k, fetch_k) - 初始化,接收向量存储、选择数量等• select_examples(input_variables) - 根据输入变量选择示例,返回示例字典列表• from_examples(examples, embeddings, vectorstore_cls, k, fetch_k) - 类方法,从示例列表创建选择器实例• vectorstore - 向量存储对象属性• k - 最终选择的示例数量属性• fetch_k - 候选集大小属性• _example_to_text(example) - 静态方法,将示例字典转换为文本• _documents_to_examples(documents) - 将文档对象列表转换为示例字典列表 |
| FAISS | FAISS 向量存储实现,用于高效的向量相似度检索和 MMR 搜索 | • __init__(embeddings) - 初始化,接收嵌入模型• add_texts(texts, metadatas) - 添加文本到向量存储• max_marginal_relevance_search(query, k, fetch_k, lambda_mult) - 最大边际相关性检索,返回文档对象列表• from_texts(texts, embeddings, metadatas) - 类方法,从文本列表创建向量存储实例• embeddings - 嵌入模型属性• index - FAISS 索引属性• documents_by_id - 文档字典属性 |
| VectorStoreExampleSelector | 基于向量存储的示例选择器基类(间接使用) | • __init__(vectorstore, k) - 初始化,接收向量存储和选择数量• vectorstore - 向量存储对象属性• k - 选择数量属性• _example_to_text(example) - 静态方法,将示例转换为文本• _documents_to_examples(documents) - 将文档对象转换为示例字典 |
| BaseExampleSelector | 示例选择器的抽象基类,定义选择器接口规范(间接使用) | • select_examples(input_variables) - 抽象方法,子类必须实现 |
| VectorStore | 向量存储抽象基类,定义向量存储接口(间接使用) | • add_texts(texts, metadatas) - 抽象方法,添加文本• max_marginal_relevance_search(query, k, fetch_k) - 抽象方法,MMR 检索• from_texts(texts, embeddings, metadatas) - 抽象类方法,从文本创建 |
| Document | 文档对象类,存储内容、元数据和嵌入向量(间接使用) | • __init__(page_content, metadata, embeddings) - 初始化文档对象• page_content - 文档内容属性• metadata - 元数据属性• embeddings - 嵌入向量属性 |
| Embeddings | 嵌入模型的抽象基类(间接使用) | • embed_query(text) - 抽象方法,单文本转向量• embed_documents(texts) - 抽象方法,多文本转向量列表 |
| AIMessage | AI 消息类,表示 AI 助手的回复消息(间接使用) | • __init__(content, **kwargs) - 初始化,type 固定为"ai"• content - 消息内容属性• type - 消息类型属性(值为"ai") |
13.5.2 类关系 #

13.5.3 类调用关系 #
13.5.4 数据流转过程 #
示例数据定义
- 创建示例字典列表,每个字典包含问题和答案
示例模板创建
- 使用
PromptTemplate.from_template()创建示例格式模板
- 使用
嵌入模型创建
- 创建
OpenAIEmbeddings实例,用于文本向量化
- 创建
MMR 选择器创建(
from_examples方法)- 转换示例为文本:使用
_example_to_text()将每个示例字典转换为文本字符串 - 创建向量存储:调用
FAISS.from_texts(),内部会:- 调用
embeddings.embed_documents()生成所有文本的嵌入向量 - 创建 FAISS 索引并添加向量
- 为每个文本创建
Document对象并存储
- 调用
- 创建选择器实例:使用创建的向量存储实例化选择器
- 转换示例为文本:使用
Few-shot 模板创建
- 使用
FewShotPromptTemplate创建模板,传入example_selector
- 使用
模板格式化
- 调用
few_shot_prompt.format(question="...") - 处理流程:
- 格式化前缀
- 调用
format_examples(input_variables) - 在
format_examples()中:- 调用
example_selector.select_examples(input_variables) - 选择器内部:
- 将输入变量转换为查询文本
- 调用
vectorstore.max_marginal_relevance_search() - FAISS 执行 MMR 检索:
- 获取查询向量
- FAISS 检索
fetch_k个候选文档 - 使用 MMR 算法选择
k个最终文档
- 将 Document 对象转换为示例字典
- 调用
- 格式化选中的示例
- 格式化后缀
- 组合所有部分
- 调用
MMR 算法原理
- 相关性:文档与查询的相似度
- 多样性:文档与已选文档的差异度
- MMR 分数:
λ × 相关性 - (1-λ) × 最大相似度 - 迭代选择:每次选择 MMR 分数最高的文档
模型调用
- 将格式化后的提示词传给
ChatOpenAI.invoke() - 返回
AIMessage对象
- 将格式化后的提示词传给
14. SemanticSimilarityExampleSelector #
SemanticSimilarityExampleSelector(语义相似度示例选择器)自动为 few-shot learning 选取与用户输入最相关的示例,实现动态 few-shot 提示生成。
基本原理
当我们希望为大语言模型(LLM)构建 few-shot 提示时,通常要选用与用户问题最接近的历史问答作为示例。但如果示例非常多,全部放入 prompt 会导致长度超限,且不够针对性。SemanticSimilarityExampleSelector 就是为此场景设计的工具:
- 示例向量化:首先将所有示例(如历史问答)用嵌入模型(如 OpenAIEmbeddings)转为向量并存入向量数据库(FAISS)。
- 动态检索:每次有新的用户问题时,自动将其与所有已存向量比较,选出最相似的几个示例。
- few-shot 拼接:只把挑出的 top-k 相似示例拼进提示词,实现“有针对性、可扩展”的 few-shot。
典型用法步骤
准备示例数据
用字典列表形式存储若干问答(见下方代码的examples)。格式化模板
使用PromptTemplate.from_template()设定如何把每个示例格式化成 prompt 子片段。嵌入向量模型
实例化OpenAIEmbeddings,用于将文本转为向量。创建选择器
调用SemanticSimilarityExampleSelector.from_examples()(传入所有示例,嵌入模型,向量存储类和 k),一键构建 selector:- 内部会对所有示例向量化,并存入 FAISS 数据库。
- 输入 query 会自动通过
similarity_search在向量空间中找最近的 k 条示例。
构建 FewShotPromptTemplate
传入 example_selector,指定如何格式化每个实例,以及前缀和后缀(通常后缀是用户的新提问)。格式化并推理
- 用
few_shot_prompt.format(question="..."),框架会自动:- 检索相似示例
- 格式化成 prompt
- 拼上前缀、后缀和用户输入
- 直接用大模型 ChatOpenAI 调用生成回复。
- 用
优势
- 动态相关性:每次自动挑选与输入最相关的 few-shot。
- 节省 prompt 长度:只塞进最有用的少量示例,避免冗余和超长。
- 零维护扩展:示例库可随时扩容,适用于 QA、工具调用、客服等任何 few-shot 场景。
和 MMR 的区别
SemanticSimilarityExampleSelector 仅用“语义相似度”判定示例是否和输入接近,选最高的前 k 个;
而前面介绍的 MaxMarginalRelevanceExampleSelector(最大边际相关性)不仅考虑“相关性”,还兼顾结果之间的“多样性”,能避免挑出内容高度重复的示例。
场景总结
- 大批量示例自动管理与查找
- 动态拼装长 prompt
- 高效 few-shot prompt 关键能力
- 可无缝迁移到工具调用、复杂数据生成等场景
14.1. 14.SemanticSimilarityExampleSelector.py #
14.SemanticSimilarityExampleSelector.py
#from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
#from langchain_core.example_selectors import SemanticSimilarityExampleSelector
#from langchain_openai import ChatOpenAI, OpenAIEmbeddings
#from langchain_community.vectorstores import FAISS
# 导入自定义的ChatOpenAI类(用于与大语言模型对话)
from smartchain.chat_models import ChatOpenAI
# 导入OpenAI的文本嵌入模型,用于将文本转换为向量
from smartchain.embeddings import OpenAIEmbeddings
# 导入提示模板PromptTemplate和FewShotPromptTemplate,用于构建few-shot提示
from smartchain.prompts import PromptTemplate, FewShotPromptTemplate
# 导入最大边际相关性(MMR)示例选择器
from smartchain.example_selectors import SemanticSimilarityExampleSelector
# 导入FAISS向量数据库实现,用于向量化检索
from smartchain.vectorstores import FAISS
# 定义10个围绕“怎样挑西瓜比较甜”等类似主题的中英文QA示例组成的列表
examples = [
{"question": "如何挑选新鲜的水果?", "answer": "观察外皮是否光滑、色泽是否自然,还可以闻闻香味,挑选表皮无破损的新鲜水果。"},
{"question": "西瓜挑选时要注意什么?", "answer": "应选择西瓜纹路清晰、瓜皮发亮,敲打有清脆声音,瓜蒂卷曲、瓜底发黄的通常比较甜。"},
{"question": "西瓜怎么挑才甜?", "answer": "用手轻轻拍打西瓜,发出清脆、沉闷有弹性之音的西瓜比较甜"},
{"question": "买水果有哪些小窍门?", "answer": "挑选时需观察颜色、闻气味、用手掂分量。对于瓜类可以敲一敲听声音来判断成熟度。"},
{"question": "怎样判断水果是否熟透?", "answer": "可以轻捏表皮,成熟的水果通常较软,闻一闻是否有浓郁的水果香味,也可以看颜色是否均匀。"},
{"question": "西瓜的黄底有什么意义?", "answer": "西瓜底部颜色越黄,通常说明在田里成熟时间长,甜度更高。"},
{"question": "挑西瓜时候能用手敲吗?", "answer": "可以,声音清脆表示瓜比较熟,声音沉闷的可能不太熟。"},
{"question": "吃西瓜对健康有哪些好处?", "answer": "西瓜含有丰富水分和多种维生素,夏季吃可补水解暑,有利于身体健康。"},
{"question": "水果要怎么保存更久?", "answer": "可存放于阴凉处,易腐水果置于冰箱冷藏,有些水果如西瓜最好切块密封保存。"},
{"question": "哪些水果适合夏天吃?", "answer": "西瓜、哈密瓜、桃子、李子等含水分高的水果特别适合夏天食用。"}
]
# 创建格式化示例的模板(把每个示例按“问题+答案”格式化为字符串)
example_prompt = PromptTemplate.from_template(
"问题:{question}\n答案:{answer}"
)
# 创建OpenAI嵌入模型实例,使能将文本转成向量
embeddings = OpenAIEmbeddings()
# 利用MMR算法和FAISS,通过from_examples方法构建最大边际相关性选择器
selector = SemanticSimilarityExampleSelector.from_examples(
examples=examples, # 传入全部示例列表
embeddings=embeddings, # 指定用OpenAIEmbedding做向量化
vectorstore_cls=FAISS, # 用FAISS作为向量检索数据库
k=3, # 最终动态挑选3个最相关的few-shot示例
)
# 构建FewShotPromptTemplate,实现自动拼接few-shot样例与用户输入
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt, # 指定样例格式模板
prefix="你是一个乐于助人的生活小助手。以下是一些建议示例:", # 固定前缀开头
suffix="问题:{question}\n答案:", # 后缀接用户本次提问
examples=examples, # 示例组成的列表
example_selector=selector # few-shot样例的动态选择器为上面构建的MMR Selector
)
# 设定本次用户的真实提问
user_question = "怎样挑西瓜比较甜?"
# 用FewShotPrompt拼接few-shot样例与用户问题,生成完整的大模型输入提示词
formatted = few_shot_prompt.format(question=user_question)
# 打印输出最终的完整Prompt(包含若干示例+用户输入)
print(formatted)
# 创建ChatOpenAI对象实例,指定用gpt-4o模型进行对话
llm = ChatOpenAI(model="gpt-4o")
# 用invoke方法向GPT发送拼好的Prompt,获得模型回复
result = llm.invoke(formatted)
# 打印“AI 回复:”的引导语
print("AI 回复:")
# 打印AI输出的真正答案内容
print(result.content)14.2. example_selectors.py #
smartchain/example_selectors.py
from abc import ABC, abstractmethod
from typing import List
from .prompts import PromptTemplate
import re
from .vectorstores import VectorStore
# 定义示例选择器的抽象基类
class BaseExampleSelector(ABC):
"""示例选择器的抽象基类"""
@abstractmethod
def select_examples(self, input_variables: dict) -> list[dict]:
"""根据输入变量选择示例"""
pass
# 定义一个基于长度的示例选择器类
class LengthBasedExampleSelector(BaseExampleSelector):
"""
基于长度的示例选择器
根据输入长度自动选择合适数量的示例,确保总长度不超过限制
"""
# 构造方法,初始化LengthBasedExampleSelector对象
def __init__(
self,
examples: list[dict], # 示例列表,每个元素为字典
example_prompt: PromptTemplate | str, # 用于格式化示例的模板,可以是PromptTemplate或字符串
max_length: int = 2048, # 提示词最大长度,默认为2048
get_text_length=None, # 可选的文本长度计算函数
):
"""
初始化 LengthBasedExampleSelector
Args:
examples: 示例列表,每个示例是一个字典
example_prompt: 用于格式化示例的模板(PromptTemplate 或字符串)
max_length: 提示词的最大长度(默认 2048)
get_text_length: 计算文本长度的函数(默认按单词数计算)
"""
# 保存所有示例到实例变量
self.examples = examples
# 如果example_prompt是字符串,则构建为PromptTemplate对象
if isinstance(example_prompt, str):
self.example_prompt = PromptTemplate.from_template(example_prompt)
# 如果已是PromptTemplate则直接赋值
else:
self.example_prompt = example_prompt
# 保存最大长度参数
self.max_length = max_length
# 设置文本长度计算函数,默认为内部定义的按单词数计算
self.get_text_length = get_text_length or self._default_get_text_length
# 计算并缓存每个示例(格式化后)的长度
self.example_text_lengths = self._calculate_example_lengths()
# 默认的长度计算方法,统计文本中的单词数
def _default_get_text_length(self, text: str) -> int:
"""
默认的长度计算函数:按单词数计算
Args:
text: 文本内容
Returns:
文本长度(单词数)
"""
# 利用正则按空白字符分割,统计词数
return len(re.split(r'\s+', text.strip()))
# 计算所有示例格式化后的长度
def _calculate_example_lengths(self) -> list[int]:
"""
计算所有示例的长度
Returns:
每个示例的长度列表
"""
# 初始化长度列表
lengths = []
# 对每个示例进行格式化并计算长度
for example in self.examples:
# 用模板对示例内容进行格式化
formatted_example = self.example_prompt.format(**example)
# 计算格式化后示例的长度
length = self.get_text_length(formatted_example)
# 记录到列表中
lengths.append(length)
# 返回长度列表
return lengths
# 根据输入内容长度,选择合适的示例列表
def select_examples(self, input_variables: dict) -> list[dict]:
"""
根据输入长度选择示例
Args:
input_variables: 输入变量字典
Returns:
选中的示例列表
"""
# 将输入的所有变量拼成一个字符串
input_text = " ".join(str(v) for v in input_variables.values())
# 计算输入内容的长度
input_length = self.get_text_length(input_text)
# 计算剩余可用长度
remaining_length = self.max_length - input_length
# 初始化选中的示例列表
selected_examples = []
# 遍历所有示例
for i, example in enumerate(self.examples):
# 如果剩余长度已经不足,提前停止选择
if remaining_length <= 0:
break
# 获取当前示例的长度
example_length = self.example_text_lengths[i]
# 判断如果再添加这个示例会超过剩余长度,则停止选择
if remaining_length - example_length < 0:
break
# 把当前示例加入已选择列表
selected_examples.append(example)
# 更新剩余可用长度
remaining_length -= example_length
# 返回最终选中的示例列表
return selected_examples
# 辅助函数:返回按字典键排序的值组成的列表
def sorted_values(values: dict) -> list:
# 对字典的键进行排序
# 依次取出对应的值组成新列表
return [values[val] for val in sorted(values)]
# 定义基于向量存储的示例选择器基类
class VectorStoreExampleSelector(BaseExampleSelector):
# 初始化方法
def __init__(
self,
vectorstore: VectorStore, # 向量存储实例对象
k: int = 4 # 需要选择的示例数量
):
# 保存向量存储对象
self.vectorstore = vectorstore
# 保存需要选择的示例数量
self.k = k
# 静态方法:将示例字典转换为一个字符串
@staticmethod
def _example_to_text(example: dict) -> str:
# 按字典键排序后拼接所有值为一个字符串
return " ".join(sorted_values(example))
# 将文档对象列表转换为示例字典列表
def _documents_to_examples(self, documents):
# 遍历每个文档对象
# 提取其元数据,并转换为字典
examples = [dict(doc.metadata) for doc in documents]
# 返回由所有示例组成的列表
return examples
# 定义最大边际相关性(MMR)示例选择器类
class MaxMarginalRelevanceExampleSelector(VectorStoreExampleSelector):
# 初始化方法
def __init__(
self,
vectorstore, # 向量存储对象
k=4, # 需要选择的最终示例数量
fetch_k=20, # 检索的候选示例数量
):
# 调用父类构造方法初始化基本参数
super().__init__(
vectorstore=vectorstore,
k=k,
)
# 保存每次检索的候选集大小
self.fetch_k = fetch_k
# 根据最大边际相关性算法,选择最终示例列表
def select_examples(self, input_variables):
# 将输入变量转成文本查询字符串
query_text = self._example_to_text(input_variables)
# 调用向量存储的最大边际相关性检索方法获取候选示例文档
example_docs = self.vectorstore.max_marginal_relevance_search(
query=query_text,
k=self.k,
fetch_k=self.fetch_k
)
# 将文档对象列表转换为标准的示例字典并返回
return self._documents_to_examples(example_docs)
# 类方法:通过一组样例创建MMR示例选择器实例
@classmethod
def from_examples(
cls, # 当前类
examples, # 示例字典列表
embeddings, # 嵌入模型实例
vectorstore_cls, # 向量存储类,如FAISS
k=4, # 最终选择几个示例
fetch_k=20, # 候选集大小
):
# 先将每个样例转换为字符串(用作向量数据库的文本)
string_examples = [
cls._example_to_text(eg) for eg in examples
]
# 使用向量存储类批量创建并加载这些样例(text->向量)
vectorstore = vectorstore_cls.from_texts(
texts=string_examples, # 文本列表
embeddings=embeddings, # 嵌入模型
metadatas=examples # 元数据列表
)
# 实例化并返回当前选择器对象
return cls(
vectorstore=vectorstore, # 构建好的向量存储实例
k=k, # 选择示例个数
fetch_k=fetch_k # 候选集大小
)
# 定义语义相似度示例选择器类,继承自VectorStoreExampleSelector
+class SemanticSimilarityExampleSelector(VectorStoreExampleSelector):
+ """
+ 基于语义相似度的示例选择器
+ 使用简单的相似度搜索来选择与查询最相似的示例。
+ 这是最直接的示例选择方法,根据与查询的语义相似度排序选择 top-k 示例。
+ """
# 定义选择示例的方法,输入为包含输入变量的字典
+ def select_examples(self, input_variables: dict) -> List[dict]:
+ """
+ 根据语义相似度选择示例
+ Args:
+ input_variables: 输入变量字典
+ Returns:
+ List[dict]: 选中的示例列表
+ """
# 将输入变量字典转换为查询文本
+ query_text = self._example_to_text(input_variables)
# 调用向量存储的similarity_search方法,检索与查询最相似的k个文档
+ example_docs = self.vectorstore.similarity_search(
+ query=query_text,
+ k=self.k
+ )
# 将检索到的文档对象转换为示例字典列表并返回
+ return self._documents_to_examples(example_docs)
# 类方法:通过一组示例和相关组件实例,创建SemanticSimilarityExampleSelector实例
+ @classmethod
+ def from_examples(
+ cls,#当前类
+ examples: List[dict],#示例列表
+ embeddings,#嵌入模型实例
+ vectorstore_cls: type,#向量存储类
+ k: int = 4#选择的示例数量 (默认4个)
+ ) -> "SemanticSimilarityExampleSelector":
+ """
+ 从示例列表创建 SemanticSimilarityExampleSelector
+ Args:
+ examples: 示例列表
+ embeddings: 嵌入模型实例
+ vectorstore_cls: 向量存储类(如 FAISS)
+ k: 选择的示例数量
+ Returns:
+ SemanticSimilarityExampleSelector: 示例选择器实例
+ """
# 遍历每个示例,将其转换为单一字符串形式组成列表
+ string_examples = [
+ cls._example_to_text(eg) for eg in examples
+ ]
# 使用vectorstore_cls批量创建向量存储对象,将文本转为向量,并将原始元数据关联
+ vectorstore = vectorstore_cls.from_texts(
+ texts=string_examples,#文本列表
+ embeddings=embeddings,#嵌入模型
+ metadatas=examples,#元数据列表
+ )
# 实例化当前类,生成选择器实例并返回
+ return cls(
+ vectorstore=vectorstore,#构建好的向量存储实例
+ k=k#选择示例个数
+ )14.3. vectorstores.py #
smartchain/vectorstores.py
# 导入os模块
import os
# 导入numpy用于数值计算
import numpy as np
# 导入抽象基类相关模块
from abc import ABC, abstractmethod
# 导入faiss库用于向量检索
import faiss
# 定义余弦相似度计算函数
def cosine_similarity(from_vec, to_vecs):
"""
计算一个向量与多个向量的余弦相似度
参数:
from_vec: 单个向量(1D或2D数组或列表)
to_vecs: 多个向量(2D或3D数组,每一行为一个向量)
返回:
一维数组,包含单个向量与每个多个向量的相似度
示例:
sims = cosine_similarity(from_vec, to_vecs)
"""
# 将from_vec转换为NumPy数组并设置为float类型
from_vec = np.array(from_vec, dtype=float)
# 将to_vecs转换为NumPy数组并设置为float类型
to_vecs = np.array(to_vecs, dtype=float)
# 计算from_vec的范数
norm1 = np.linalg.norm(from_vec)
# 如果from_vec为零向量,直接返回全0相似度数组
if norm1 == 0:
return np.zeros(len(to_vecs))
# 初始化相似度结果列表
similarities = []
# 遍历每一个目标向量to_vec
for to_vec in to_vecs:
# 计算from_vec和to_vec的点积
dot_product = np.sum(from_vec * to_vec)
# 计算to_vec的范数
norm_vec = np.linalg.norm(to_vec)
# 如果to_vec为零向量,相似度记为0
if norm_vec == 0:
similarities.append(0.0)
else:
# 计算余弦相似度
similarity = dot_product / (norm1 * norm_vec)
similarities.append(similarity)
# 返回相似度结果的NumPy数组
return np.array(similarities)
# 定义最大边际相关性(MMR)算法函数
def mmr_select(query_vector, doc_vectors, k=3, lambda_mult=0.5):
"""
使用最大边际相关性(MMR)算法选择文档
参数:
query_vector: 查询向量(1D数组)
doc_vectors: 文档向量集合(2D数组,每行一个文档向量)
k: 要选择的文档数量(默认3)
lambda_mult: λ参数,平衡相关性与多样性(默认0.5)
- λ=1: 只看相关性
- λ=0: 只看多样性
- λ=0.5: 平衡相关性和多样性
返回:
selected: 选中的文档索引列表(从0开始)
示例:
selected = mmr_select(query_vector, doc_vectors, k=3, lambda_mult=0.5)
"""
# 计算所有文档与查询向量的余弦相似度
query_similarities = cosine_similarity(query_vector, doc_vectors)
# 打印每个文档与查询的相关性分数
print("文档与查询的相关性分数:")
for i, sim in enumerate(query_similarities):
# 打印文档编号及对应相似度
print(f"文档{i+1}: {sim:.4f}")
# 选中相关性最高的文档索引,作为第一个已选文档
selected = [int(np.argmax(query_similarities))]
# 直到已选择k个文档之前循环
while len(selected) < k:
# 初始化MMR分数列表
mmr_scores = []
# 遍历所有文档索引
for i in range(len(doc_vectors)):
# 如果该文档还未被选中
if i not in selected:
# 当前文档与查询的相关性分数
relevance = query_similarities[i]
# 获取已选文档的向量集合
selected_vecs = doc_vectors[selected]
# 计算当前文档与已选各文档的余弦相似度
sims = cosine_similarity(doc_vectors[i], selected_vecs)
# 获取与已选文档中最大相似度(最不多样的)
max_sim = np.max(sims)
# 按MMR公式计算分数
mmr_score = lambda_mult * relevance - (1 - lambda_mult) * max_sim
# 记录文档编号和对应的MMR分数
mmr_scores.append((i, mmr_score))
# 如果没有可选文档就跳出循环
if not mmr_scores:
break
# 选取MMR分数最高的文档编号
best_idx, best_score = max(mmr_scores, key=lambda x: x[1])
# 将该文档编号加入已选列表
selected.append(best_idx)
# 返回已选中文档的索引
return selected
# 定义Document文档对象类
class Document:
# 文档类,存储内容、元数据和嵌入向量
def __init__(self, page_content: str, metadata=None, embedding_value=None):
# 初始化文档内容
self.page_content = page_content
# 初始化元数据,默认空字典
self.metadata = metadata or {}
# 初始化嵌入向量
self.embedding_value = embedding_value
# 定义向量存储抽象基类
class VectorStore(ABC):
# 向量存储抽象基类
# 抽象方法,添加文本到向量存储
@abstractmethod
def add_texts(
self,
texts,
metadatas=None
):
# 添加文本方法为抽象方法,由子类实现
pass
# 抽象方法,最大边际相关性检索
@abstractmethod
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20
):
# 最大边际相关性检索方法为抽象方法,由子类实现
pass
+ @abstractmethod
+ def similarity_search(
+ self,
+ query: str,
+ k: int = 4
+ ):
+ """相似度搜索"""
+ pass
# 抽象类方法,从文本批量构造向量存储
@classmethod
@abstractmethod
def from_texts(
cls,
texts,
embeddings,
metadatas=None
):
# 批量通过文本构建向量存储的抽象方法,由子类实现
pass
# 定义FAISS向量存储类,继承自VectorStore
class FAISS(VectorStore):
# FAISS向量存储实现
def __init__(
self,
embeddings, # 嵌入模型
):
# 保存嵌入模型
self.embeddings = embeddings
# 初始化FAISS索引为空
self.index = None
# 初始化文档字典,键为文档id,值为Document对象
self.documents_by_id = {}
# 添加文本到向量存储
def add_texts(
self,
texts,
metadatas=None
):
# 如果未传入元数据,则使用空字典列表
if metadatas is None:
metadatas = [{}] * len(texts)
# 利用嵌入模型生成文本的嵌入向量
embedding_values = self.embedding.embed_documents(texts)
# 转换成float32类型的NumPy数组
embedding_values = np.array(embedding_values, dtype=np.float32)
# 若还未建立FAISS索引,则新建之
if self.index is None:
dimension = len(embedding_values[0])
self.index = faiss.IndexFlatL2(dimension)
# 添加嵌入向量到FAISS索引
self.index.add(embedding_values)
# 获取当前已有文档数量,用于新文档编号
start_idx = len(self.documents_by_id)
# 遍历插入的每组文本、元数据、嵌入向量
for i, (text, metadata, embedding) in enumerate(zip(texts, metadatas, embedding_values)):
# 构造文档id
doc_id = str(start_idx + i)
# 构造Document对象
doc = Document(page_content=text, metadata=metadata, embedding_value=embedding_value)
# 保存进字典
self.documents_by_id[doc_id] = doc
# 最大边际相关性检索方法
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5,
):
# 获取查询文本的嵌入向量
query_embedding = self.embedding.embed_query(query)
# 转为二维NumPy数组
query_vector = np.array([query_embedding], dtype=np.float32) # (1, dimension)
# 用FAISS索引检索出fetch_k个候选文档(距离最近)
if isinstance(self.index, faiss.Index):
# 执行检索,返回索引及距离
_, indices = self.index.search(query_vector, fetch_k)
# 解析获得候选文档的索引列表
candidate_indices = indices[0]
else:
# 非法索引则抛出异常
raise RuntimeError("FAISS index is not available.")
# 如果候选文档不足k个,直接返回这些文档
if len(candidate_indices) <= k:
docs = []
for idx in candidate_indices:
doc_id = str(idx)
# 存在于字典才添加
if doc_id in self.documents_by_id:
docs.append(self.documents_by_id[doc_id])
return docs
# 从字典中提取候选文档的嵌入向量
candidate_vectors = np.array([self.documents_by_id[str(i)].embedding_value for i in candidate_indices], dtype=np.float32)
# 通过mmr_select获取MMR选出的下标
selected_indices = mmr_select(query_embedding, candidate_vectors, k=k, lambda_mult=lambda_mult)
# 根据选出下标获得最终文档对象
docs = []
for idx in selected_indices:
doc_id = str(candidate_indices[idx])
if doc_id in self.documents_by_id:
docs.append(self.documents_by_id[doc_id])
return docs
# 定义相似度检索方法,返回与查询最近的k个文档
+ def similarity_search(
+ self,
+ query: str,
+ k: int = 4
+ ):
+ """
+ 相似度搜索
+ Args:
+ query: 查询文本
+ k: 返回的文档数量
+ Returns:
+ List[Document]: 最相似的文档列表
+ """
# 获取查询文本的嵌入向量
+ query_embedding = self.embeddings.embed_query(query)
# 将嵌入向量转换为NumPy二维数组(形状为1行,d维)
+ query_vector = np.array([query_embedding], dtype=np.float32)
# 用FAISS索引执行k近邻检索,得到距离最近的k个索引
+ _, indices = self.index.search(query_vector, k)
# 创建用于存放检索到文档对象的列表
+ docs = []
# 遍历返回的每个文档索引
+ for idx in indices[0]:
# 把数字索引转为字符串形式的文档id
+ doc_id = str(idx)
# 只有字典中存在这个id的文档才加入最终结果
+ if doc_id in self.documents_by_id:
+ docs.append(self.documents_by_id[doc_id])
# 返回最终的相似文档列表
+ return docs
# 类方法:通过文本批量创建FAISS向量存储实例
@classmethod
def from_texts(
cls,
texts,
embeddings,
metadatas=None
):
# 创建FAISS实例
instance = cls(embeddings=embeddings)
# 添加全部文本及元数据
instance.add_texts(texts=texts, metadatas=metadatas)
# 返回构建好的实例
return instance14.4 类 #
14.4.1 类说明 #
| 类名 | 主要功能 | 关键方法 |
|---|---|---|
| ChatOpenAI | 与大语言模型对话的封装类 | __init__(), invoke(), stream() |
| OpenAIEmbeddings | 将文本转换为向量嵌入 | __init__(), embed_query(), embed_documents() |
| PromptTemplate | 字符串模板格式化类 | __init__(), from_template(), format() |
| FewShotPromptTemplate | 构建 few-shot 提示词模板 | __init__(), format(), format_examples() |
| SemanticSimilarityExampleSelector | 基于语义相似度的示例选择器 | __init__(), from_examples(), select_examples() |
| FAISS | 向量存储和检索实现 | __init__(), from_texts(), similarity_search(), add_texts() |
14.4.2 类图 #
14.4.3 流程图 #
14.4.4 调用过程 #
初始化阶段
步骤1:创建嵌入模型(第37行)
embeddings = OpenAIEmbeddings()- 创建
OpenAIEmbeddings实例,用于文本向量化
步骤2:创建示例选择器(第40-45行)
selector = SemanticSimilarityExampleSelector.from_examples(
examples=examples,
embeddings=embeddings,
vectorstore_cls=FAISS,
k=3,
)内部流程:
from_examples将每个示例字典转为字符串:string_examples = [" ".join(sorted(example.values())) for example in examples]- 调用
FAISS.from_texts():- 使用
embeddings.embed_documents()将文本转为向量 - 构建 FAISS 索引(L2 距离)
- 将示例元数据关联到文档
- 使用
- 返回
SemanticSimilarityExampleSelector实例
步骤3:创建 Few-Shot 模板(第48-53行)
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt,
prefix="你是一个乐于助人的生活小助手。以下是一些建议示例:",
suffix="问题:{question}\n答案:",
example_selector=selector
)- 保存
example_selector,用于动态选择示例
运行时阶段
步骤1:格式化提示词(第58行)
formatted = few_shot_prompt.format(question=user_question)内部流程:
FewShotPromptTemplate.format()被调用- 检查输入变量是否完整
- 调用
format_examples(input_variables=kwargs)
步骤2:选择示例(在 format_examples 中)
selected_examples = self.example_selector.select_examples(input_variables)SemanticSimilarityExampleSelector.select_examples() 流程:
- 将输入变量转为查询文本:
query_text = self._example_to_text({"question": "怎样挑西瓜比较甜?"}) # 结果: "怎样挑西瓜比较甜?" - 调用向量存储检索:
example_docs = self.vectorstore.similarity_search(query=query_text, k=3) FAISS.similarity_search()执行:- 使用
embeddings.embed_query(query_text)获取查询向量 - 通过 FAISS 索引进行 k 近邻检索(L2 距离)
- 返回最相似的 3 个
Document对象
- 使用
- 将文档转为示例字典:
examples = [dict(doc.metadata) for doc in example_docs]
步骤3:格式化示例并拼接
- 使用
example_prompt.format()格式化每个选中示例 - 拼接:
prefix + 格式化示例 + suffix - 返回完整提示词字符串
步骤4:调用大语言模型(第65行)
result = llm.invoke(formatted)ChatOpenAI.invoke() 流程:
_convert_input()将字符串转为 OpenAI 消息格式- 调用 OpenAI API
- 解析响应,返回
AIMessage对象
核心算法说明
语义相似度计算 使用余弦相似度(通过 L2 距离近似): $$\text{similarity}(q, d) = \frac{q \cdot d}{||q|| \cdot ||d||}$$
在 FAISS 中,使用 L2 距离: $$\text{distance}(q, d) = ||q - d||_2$$
相似度越高,距离越小。
示例选择策略
SemanticSimilarityExampleSelector 选择与查询最相似的 k 个示例:
- 将查询文本向量化
- 在向量空间中检索 k 个最近邻
- 返回对应的原始示例
五、数据流转图
原始示例列表 (examples)
↓
[SemanticSimilarityExampleSelector.from_examples]
↓
文本向量化 (OpenAIEmbeddings.embed_documents)
↓
FAISS索引构建 (存储向量 + 元数据)
↓
[用户查询] → 查询向量化 → FAISS检索 → 选中3个示例
↓
[FewShotPromptTemplate.format]
↓
格式化示例 + 拼接prefix/suffix
↓
完整提示词字符串
↓
[ChatOpenAI.invoke]
↓
AI回复 (AIMessage)15. BaseExampleSelector #
自定义的示例选择器(KeywordBasedExampleSelector),用于 Few-Shot Prompt 场景下根据用户输入自动选择与之最相关的示例。这一选择器的核心思路是:对输入内容及每个示例进行关键词分词,统计关键词重叠度(相同关键词数量),返回重叠最多的前k个示例。
关键功能
- 分词与关键词提取:利用
jieba分词库能同时处理中文、英文混合文本。中文关键词需超过 1 个汉字,英文则自动归一为小写,保证匹配更智能。 - 相关性打分:逐一计算用户输入与每个示例之间的关键词交集数量,按得分降序排序。
- 灵活的k与匹配阈值:参数
k决定最多返回几个示例,min_keyword_match控制入选示例的最小关键词重叠阈值。这样可以避免无关示例入选。 - 补齐机制:若合格示例数量不满
k,则补充其余示例填满。
应用场景
当你希望大模型提示词(Prompt)前带有若干代表性问答示例,用于 One-shot 或 Few-shot 迁移学习,引导模型风格/格式时,可以:
- 采用本选择器,自动筛选最相关的案例而非固定死板示例。
- 按语义和关键词接近度,提升 LLM 对用户输入的理解与生成质量。
- 十分适合中文 COT/任务导向的类助手模型、问答系统场景。
用法流程
- 定义承载示例的
examples(每项含question和answer)。 - 创建
KeywordBasedExampleSelector并传入examples。 - 配合
FewShotPromptTemplate,实现自动挑选示例+拼接 Prompt。 - 构建最终 Prompt 喂给大模型,拿到回答。
15.1. 15.BaseExampleSelector.py #
15.BaseExampleSelector.py
# 导入 langchain_core 的提示模板和 few-shot 提示模板
#from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
# 导入基础示例选择器基类
#from langchain_core.example_selectors import BaseExampleSelector
# 导入 OpenAI 的对话模型及嵌入模型
#from langchain_openai import ChatOpenAI
from smartchain.chat_models import ChatOpenAI
from smartchain.prompts import PromptTemplate, FewShotPromptTemplate
from smartchain.example_selectors import BasedExampleSelector
# 导入正则表达式模块
import re
# 导入中文分词包 jieba
import jieba
# 定义自定义的基于关键词匹配的示例选择器,继承 BasedExampleSelector
class KeywordBasedExampleSelector(BasedExampleSelector):
"""
基于关键词匹配的自定义示例选择器
这个选择器会根据输入中的关键词来选择最相关的示例。
它计算输入和示例之间的关键词重叠度,选择重叠度最高的示例。
"""
# 构造函数,初始化参数
def __init__(
self,
examples,
k = 3,
input_key: str = "question",
min_keyword_match = 1,
):
"""
初始化关键词选择器
Args:
examples: 示例列表
k: 选择的示例数量
input_key: 用于匹配的输入键名
min_keyword_match: 最少匹配的关键词数量
"""
# 保存示例列表
self.examples = examples
# 需要选择返回的示例个数
self.k = k
# 指定比较的字段
self.input_key = input_key
# 匹配的最小关键词个数
self.min_keyword_match = min_keyword_match
# 私有方法,提取中文和英文关键词
def _extract_keywords(self, text: str):
"""
从文本中提取关键词(中文和英文)
Args:
text: 输入文本
Returns:
set: 关键词集合
"""
# 用集合存储关键词,防止重复
keywords = set()
# 使用 jieba 分词,支持中英文混合
words = jieba.cut(text)
for word in words:
# 去除两端空白
word = word.strip()
# 跳过空字符串
if not word:
continue
# 中文关键词:必须全是中文且长度大于1
if re.match(r'^[\u4e00-\u9fa5]+$', word):
if len(word) > 1:
keywords.add(word)
# 英文关键词直接转小写加入
elif re.match(r'^[a-zA-Z]+$', word):
keywords.add(word.lower())
# 返回关键词集合
return keywords
# 私有方法,计算输入和示例文本的关键词重叠数量
def _calculate_match_score(self, input_text: str, example_text: str) -> int:
"""
计算输入文本和示例文本的匹配分数
Args:
input_text: 输入文本
example_text: 示例文本
Returns:
int: 匹配分数(关键词重叠数量)
"""
# 获取输入文本提取出的关键词集合
input_keywords = self._extract_keywords(input_text)
# 获取示例文本提取出的关键词集合
example_keywords = self._extract_keywords(example_text)
# 计算并返回交集(重叠关键词)的数量
return len(input_keywords & example_keywords)
# 主方法,根据输入选择最相关示例
def select_examples(self, input_variables):
"""
根据关键词匹配选择示例
Args:
input_variables: 输入变量字典
Returns:
选中的示例列表
"""
# 从输入变量中获取实际要比较的字段
input_text = input_variables.get(self.input_key, "")
# 如果输入内容为空,直接返回前k个示例
if not input_text:
return self.examples[:self.k]
# 用列表存放所有达到匹配要求的(分数, 示例)
scored_examples = []
for example in self.examples:
# 取出当前示例里的主要字段
example_text = example.get(self.input_key, "")
# 计算匹配分数
score = self._calculate_match_score(input_text, example_text)
# 如果分数满足最小关键词匹配数,收集该示例
if score >= self.min_keyword_match:
scored_examples.append((score, example))
# 按分数从高到低排序
scored_examples.sort(key=lambda x: x[0], reverse=True)
# 只取前k个高分示例
selected = [example for _, example in scored_examples[:self.k]]
# 如果还不足k个,则补齐其它未被选中的示例
if len(selected) < self.k:
remaining = [ex for ex in self.examples if ex not in selected]
selected.extend(remaining[:self.k - len(selected)])
# 返回最终选中的示例
return selected
# 创建示例列表,每个包含'question'和'answer'
examples = [
{"question": "今天天气怎么样?", "answer": "今天天气晴朗,适合出门活动。"},
{"question": "怎么做西红柿炒鸡蛋?", "answer": "先把西红柿和鸡蛋切好,鸡蛋炒熟后盛出,再炒西红柿,最后把鸡蛋倒回去一起炒匀即可。"},
{"question": "如何快速减肥?", "answer": "合理饮食结合锻炼,每天保持运动,避免高热量食物。"},
{"question": "手机没电了怎么办?", "answer": "用充电器充电,或者借用移动电源。"},
{"question": "头疼该怎么办?", "answer": "多休息,如果严重可以适当吃点止痛药。"},
{"question": "怎样养护盆栽?", "answer": "定期浇水,保持阳光,不要积水。"},
{"question": "想学英语怎么入门?", "answer": "可以先从背单词、学基础语法和多听多说开始。"},
{"question": "晚上失眠怎么办?", "answer": "睡前放松,避免咖啡因,可以听点轻音乐帮助入睡。"},
{"question": "烧水壶如何清理水垢?", "answer": "可以倒入一点醋和水煮几分钟,再用清水冲洗干净。"},
{"question": "手机上怎么截图?", "answer": "可以同时按住电源键和音量减键进行截图,不同手机略有区别。"},
]
# 创建示例输出格式模板
example_prompt = PromptTemplate.from_template(
"问题:{question}\n答案:{answer}"
)
# 创建基于关键词的示例选择器
keyword_selector = KeywordBasedExampleSelector(
examples=examples,
k=3,
input_key="question",
min_keyword_match=1,
)
# 创建 FewShotPromptTemplate,其中 example_selector 使用自定义的 keyword_selector
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt,
prefix="你是一个乐于助人的生活小助手。以下是一些建议示例:",
suffix="问题:{question}\n答案:",
examples=examples,
example_selector=keyword_selector, # 使用自定义选择器
)
# 用户输入的问题
user_question = "手机没信号怎么办?"
# 格式化出带有示例和用户问题的完整提示词
formatted = few_shot_prompt.format(question=user_question)
# 打印生成的提示词文本
print(formatted)
# 初始化 ChatOpenAI,指定模型为 gpt-4o
llm = ChatOpenAI(model="gpt-4o")
# 执行 LLM 推理并获得回复
result = llm.invoke(formatted)
# 打印 AI 回复内容
print("AI 回复:")
print(result.content)
15.4 类 #
15.4.1 类说明 #
| 类名 | 主要功能 | 关键方法 |
|---|---|---|
| BaseExampleSelector | 示例选择器的抽象基类 | select_examples(input_variables: dict) (抽象方法) |
| KeywordBasedExampleSelector | 基于关键词匹配的示例选择器 | __init__(), select_examples(), _extract_keywords(), _calculate_match_score() |
| PromptTemplate | 字符串模板格式化类 | __init__(), from_template(), format() |
| FewShotPromptTemplate | 构建 few-shot 提示词模板 | __init__(), format(), format_examples() |
| ChatOpenAI | 与大语言模型对话的封装类 | __init__(), invoke(), stream() |
15.4.2 类图 #
15.4.3 流程图 #
15.4.4 调用过程 #
15.4.4.1 初始化阶段 #
步骤1:创建示例格式化模板(第159-161行)
example_prompt = PromptTemplate.from_template(
"问题:{question}\n答案:{answer}"
)- 创建
PromptTemplate,用于格式化每个示例
步骤2:创建自定义示例选择器(第164-169行)
keyword_selector = KeywordBasedExampleSelector(
examples=examples,
k=3,
input_key="question",
min_keyword_match=1,
)KeywordBasedExampleSelector.__init__() 流程:
- 保存示例列表:
self.examples = examples - 设置参数:
k=3:选择 3 个示例input_key="question":从输入变量中取question字段min_keyword_match=1:至少匹配 1 个关键词
步骤3:创建 Few-Shot 模板(第172-177行)
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt,
prefix="你是一个乐于助人的生活小助手。以下是一些建议示例:",
suffix="问题:{question}\n答案:",
example_selector=keyword_selector,
)- 保存
example_selector引用,用于动态选择示例
15.4.4.2 运行时阶段 #
步骤1:格式化提示词(第182行)
formatted = few_shot_prompt.format(question=user_question)步骤2:选择示例(在 FewShotPromptTemplate.format() 内部)
当 FewShotPromptTemplate.format_examples() 被调用时:
if self.example_selector:
selected_examples = self.example_selector.select_examples(input_variables)步骤3:关键词提取和匹配(KeywordBasedExampleSelector.select_examples())
详细流程:
获取输入文本(第114行):
input_text = input_variables.get(self.input_key, "") # input_text = "手机没信号怎么办?"提取输入关键词(第96行调用
_extract_keywords()):def _extract_keywords(self, text: str): keywords = set() words = jieba.cut(text) # 使用jieba分词 for word in words: word = word.strip() if re.match(r'^[\u4e00-\u9fa5]+$', word) and len(word) > 1: keywords.add(word) # 中文关键词 elif re.match(r'^[a-zA-Z]+$', word): keywords.add(word.lower()) # 英文关键词 return keywords- 输入:"手机没信号怎么办?"
- 提取关键词:
{"手机", "信号"}
遍历示例并计算匹配分数(第121-128行):
for example in self.examples: example_text = example.get(self.input_key, "") score = self._calculate_match_score(input_text, example_text) if score >= self.min_keyword_match: scored_examples.append((score, example))计算匹配分数(
_calculate_match_score()方法,第84-100行):def _calculate_match_score(self, input_text: str, example_text: str) -> int: input_keywords = self._extract_keywords(input_text) example_keywords = self._extract_keywords(example_text) return len(input_keywords & example_keywords) # 集合交集示例匹配:
- 示例1:"手机没电了怎么办?" → 关键词:
{"手机"}→ 匹配分数:1 - 示例2:"怎么做西红柿炒鸡蛋?" → 关键词:
{"西红柿", "鸡蛋"}→ 匹配分数:0 - 示例3:"今天天气怎么样?" → 关键词:
{"天气"}→ 匹配分数:0
- 示例1:"手机没电了怎么办?" → 关键词:
排序并选择 top-k(第131-134行):
scored_examples.sort(key=lambda x: x[0], reverse=True) # 按分数降序 selected = [example for _, example in scored_examples[:self.k]]- 选择匹配分数最高的 3 个示例
补齐不足的示例(第137-139行):
if len(selected) < self.k: remaining = [ex for ex in self.examples if ex not in selected] selected.extend(remaining[:self.k - len(selected)])
步骤4:格式化示例并拼接(在 FewShotPromptTemplate 中)
格式化每个选中示例(调用
example_prompt.format()):for example in selected_examples: formatted.append(self.example_prompt.format(**example))拼接完整提示词:
prefix + 格式化示例1 + 格式化示例2 + 格式化示例3 + suffix
步骤5:调用大语言模型(第189行)
result = llm.invoke(formatted)ChatOpenAI.invoke() 流程:
_convert_input()将字符串转换为 OpenAI 消息格式- 调用 OpenAI API
- 解析响应,返回
AIMessage对象
15.4.4.3 核心算法说明 #
关键词提取算法
使用 jieba 分词,提取规则:
- 中文关键词:全为中文且长度 > 1
- 英文关键词:全为字母,转为小写
匹配分数计算
使用集合交集计算重叠关键词数量:
$$\text{score} = |K_{\text{input}} \cap K_{\text{example}}|$$
其中:
- $K_{\text{input}}$ 是输入文本的关键词集合
- $K_{\text{example}}$ 是示例文本的关键词集合
示例选择策略
- 计算所有示例的匹配分数
- 过滤:
score >= min_keyword_match - 按分数降序排序
- 选择 top-k 个示例
- 若不足 k 个,从剩余示例中补齐
15.4.4.5 数据流转图 #
原始示例列表 (examples)
↓
[KeywordBasedExampleSelector.__init__]
↓
保存示例列表和参数
↓
[用户查询] → 提取关键词 → 计算匹配分数 → 排序选择top-k
↓
选中3个示例
↓
[FewShotPromptTemplate.format]
↓
格式化示例 (PromptTemplate.format)
↓
拼接prefix + examples + suffix
↓
完整提示词字符串
↓
[ChatOpenAI.invoke]
↓
AI回复 (AIMessage)15.4.4.6 与 SemanticSimilarityExampleSelector 的对比 #
| 特性 | KeywordBasedExampleSelector | SemanticSimilarityExampleSelector |
|---|---|---|
| 匹配方式 | 关键词重叠(集合交集) | 语义相似度(向量余弦相似度) |
| 依赖 | jieba 分词库 | OpenAI Embeddings + FAISS |
| 计算复杂度 | O(n×m)(n=示例数,m=平均关键词数) | O(n×d)(d=向量维度,通常更高) |
| 准确性 | 基于字面匹配,可能遗漏语义相似 | 基于语义理解,更准确 |
| 性能 | 快速,无需 API 调用 | 较慢,需要向量化 API 调用 |
| 适用场景 | 关键词明确、快速响应 | 语义理解要求高、示例量大 |