16.StrOutputParser #
- StrOutputParser 是一个用于处理大语言模型(LLM)输出的工具类,它的核心作用是将模型返回的内容标准化为字符串类型。
- 在大多数自然语言处理场景中,模型的输出一般为字符串,但有时输出可能因为链式调用、流式输出、或API封装等原因而被包装成其他类型(如一些对象、嵌套结构等)。
- StrOutputParser 的设计目标就是确保最终交给下游环节的内容始终为字符串,这样可以大大简化后续处理的复杂度,保证数据的一致性。
主要功能
- 类型统一:自动将所有输入(不管原始类型如何)转为字符串,避免因类型不一致造成的潜在错误。
- 零副作用:不会修改原始内容,仅做类型转换。
- 易于集成:可以和各种 LLM 调用结果直接结合,是流水线/链路中的标准输出类型转换器。
使用场景举例
- 直接解析模型响应:适用于你只关心字符串文本内容、无需结构化处理的绝大多数应用。
- 与流式输出结合:当流式返回多个内容片段并拼接后,可用此解析器统一输出为完整字符串。
- 链式调用统一格式:在多步管道(pipeline)中,确保各环节传递的数据始终为字符串。
16.1. 16.StrOutputParser.py #
16.StrOutputParser.py
# 导入字符串输出解析器,用于对模型返回结果进行字符串化处理
#from langchain_core.output_parsers import StrOutputParser
# 导入OpenAI对话模型接口
#from langchain_openai.chat_models import ChatOpenAI
from smartchain.chat_models import ChatOpenAI
from smartchain.output_parsers import StrOutputParser
# 创建一个 ChatOpenAI 对象,指定使用 "gpt-4o" 模型
llm = ChatOpenAI(model="gpt-4o")
# 创建字符串输出解析器对象
parser = StrOutputParser()
# 调用模型生成一句话介绍 Python 编程语言
response = llm.invoke("请用一句话介绍 Python 编程语言。")
# 用字符串输出解析器对模型输出内容进行解析得到纯字符串
parsed_output = parser.parse(response.content)
# 打印解析后的内容
print(f"解析后内容:{parsed_output}")
# 打印解析后内容的数据类型
print(f"解析后类型:{type(parsed_output)}")
# 调用模型以流式方式生成三句话介绍人工智能
stream = llm.stream("请用三句话介绍人工智能")
# 初始化变量用于接收模型的流式输出
full_response = ""
# 遍历流式输出的每一个内容块
for chunk in stream:
# 取出内容,如果 chunk 有 content 属性则取之,否则直接转为字符串
content = chunk.content if hasattr(chunk, 'content') else str(chunk)
# 实时打印内容(不换行,flush保证及时输出)
print(content, end="", flush=True)
# 追加到完整响应字符串中
full_response += content
# 用字符串解析器对流式返回的完整内容进行解析
parsed_stream = parser.parse(full_response)
# 打印解析后的完整输出
print(f"解析后的完整输出:{parsed_stream}")
# 打印解析后完整输出的数据类型
print(f"解析后类型:{type(parsed_stream)}")
16.2. output_parsers.py #
smartchain/output_parsers.py
# 导入抽象类基类(ABC)和抽象方法(abstractmethod)
from abc import ABC, abstractmethod
# 定义输出解析器的抽象基类
class BaseOutputParser(ABC):
"""输出解析器的抽象基类"""
# 定义抽象方法 parse,需要子类实现具体的解析逻辑
@abstractmethod
def parse(self, text):
"""
解析输出文本
Args:
text: 要解析的文本
Returns:
解析后的结果
"""
# 抽象方法体,实际不会执行,只是作为接口约束
pass
# 定义字符串输出解析器类,继承自 BaseOutputParser
class StrOutputParser(BaseOutputParser):
"""
字符串输出解析器
将 LLM 的输出解析为字符串。这是最简单的输出解析器,
它不会修改输入内容,只是确保输出是字符串类型。
主要用于:
- 确保 LLM 输出是字符串类型
- 在链式调用中统一输出格式
- 简化输出处理流程
"""
# 实现 parse 方法,将输入内容原样返回为字符串
def parse(self, text: str) -> str:
"""
解析输出文本(实际上只是返回原文本)
Args:
text: 输入文本(应该是字符串)
Returns:
str: 原样返回输入文本
"""
# 如果输入不是字符串,则将其转换为字符串类型
if not isinstance(text, str):
return str(text)
# 如果已经是字符串,则直接返回
return text
# 定义 __repr__ 方法,返回该解析器的字符串表示
def __repr__(self) -> str:
"""返回解析器的字符串表示"""
return "StrOutputParser()"16.3. 类 #
16.3.1 类说明 #
| 类名 | 作用 | 主要方法 | 说明 |
|---|---|---|---|
| ChatOpenAI | OpenAI 对话模型封装类 | __init__(), invoke(), stream(), _convert_input() |
封装 OpenAI API 调用,支持同步和流式调用 |
| StrOutputParser | 字符串输出解析器 | parse() |
将 LLM 输出解析为字符串类型 |
| BaseOutputParser | 输出解析器抽象基类 | parse() (抽象方法) |
定义输出解析器的接口规范 |
| AIMessage | AI 消息类 | __init__(), __repr__() |
封装 AI 模型返回的消息内容 |
| BaseMessage | 消息基类 | __init__(), __str__(), __repr__() |
所有消息类型的基类,包含 content 属性 |
ChatOpenAI
| 方法 | 参数 | 返回值 | 功能描述 |
|---|---|---|---|
__init__(model, **kwargs) |
model: 模型名称**kwargs: 其他参数(如 api_key) |
无 | 初始化 ChatOpenAI 实例,设置模型和 API 密钥 |
invoke(input, **kwargs) |
input: 输入内容(字符串或消息列表)**kwargs: 额外参数 |
AIMessage |
同步调用模型生成完整回复 |
stream(input, **kwargs) |
input: 输入内容**kwargs: 额外参数 |
生成器(yield AIMessage) | 流式调用模型,逐块返回回复 |
_convert_input(input) |
input: 输入内容 |
list[dict] |
将各种格式的输入转换为 OpenAI API 期望的消息格式 |
StrOutputParser
| 方法 | 参数 | 返回值 | 功能描述 |
|---|---|---|---|
parse(text) |
text: 要解析的文本 |
str |
将输入文本转换为字符串类型(如果已经是字符串则直接返回) |
AIMessage
| 属性/方法 | 说明 |
|---|---|
content |
消息内容(字符串) |
type |
消息类型(固定为 "ai") |
__init__(content, **kwargs) |
初始化 AI 消息,设置内容和类型 |
16.3.2 类图 #
类关系说明
继承关系:
AIMessage继承自BaseMessageStrOutputParser继承自BaseOutputParser
依赖关系:
ChatOpenAI.invoke()和ChatOpenAI.stream()方法返回AIMessage对象StrOutputParser.parse()方法接收AIMessage.content作为输入
组合关系:
ChatOpenAI内部包含OpenAI客户端对象
16.3.3 时序图 #
16.3.3.1 同步调用流程(invoke 方法) #
16.3.3.2 流式调用流程(stream 方法) #
16.3.4 调用过程 #
阶段一:初始化阶段(第 10-12 行)
llm = ChatOpenAI(model="gpt-4o")
parser = StrOutputParser()执行过程:
创建
ChatOpenAI实例:- 设置
model = "gpt-4o" - 从环境变量或参数获取
api_key - 初始化 OpenAI 客户端:
self.client = openai.OpenAI(api_key=self.api_key)
- 设置
创建
StrOutputParser实例:- 继承自
BaseOutputParser - 实现
parse()方法用于字符串解析
- 继承自
阶段二:同步调用流程(第 15-21 行)
response = llm.invoke("请用一句话介绍 Python 编程语言。")
parsed_output = parser.parse(response.content)详细步骤:
调用
invoke()方法:输入: "请用一句话介绍 Python 编程语言。" ↓ _convert_input() 转换: [{"role": "user", "content": "请用一句话介绍 Python 编程语言。"}] ↓ 调用 OpenAI API: client.chat.completions.create(model="gpt-4o", messages=[...]) ↓ 接收响应: response.choices[0].message.content ↓ 返回: AIMessage(content="Python 是一种高级编程语言...")解析输出:
parser.parse(response.content) ↓ 检查: isinstance(text, str) ↓ 返回: str 类型(原样返回或转换为字符串)
阶段三:流式调用流程(第 24-42 行)
stream = llm.stream("请用三句话介绍人工智能")
for chunk in stream:
content = chunk.content if hasattr(chunk, 'content') else str(chunk)
print(content, end="", flush=True)
full_response += content
parsed_stream = parser.parse(full_response)详细步骤:
调用
stream()方法:输入: "请用三句话介绍人工智能" ↓ _convert_input() 转换: [{"role": "user", "content": "请用三句话介绍人工智能"}] ↓ 调用 OpenAI API (stream=True): client.chat.completions.create(..., stream=True) ↓ 返回生成器对象迭代流式响应:
for chunk in stream: ↓ 每次迭代返回一个 AIMessage 对象 ↓ 提取 chunk.content(字符串片段) ↓ 实时打印并累积到 full_response解析完整响应:
parser.parse(full_response) ↓ 将累积的完整字符串转换为 str 类型 ↓ 返回解析后的字符串
16.3.5 数据流转过程 #
16.3.5.1 同步调用数据流 #
用户输入(字符串)
↓
ChatOpenAI._convert_input()
↓
OpenAI API 格式: [{"role": "user", "content": "..."}]
↓
OpenAI API 调用
↓
API 响应: response.choices[0].message.content
↓
AIMessage(content="...")
↓
response.content(字符串)
↓
StrOutputParser.parse()
↓
最终输出(字符串)16.3.5.2 流式调用数据流 #
用户输入(字符串)
↓
ChatOpenAI._convert_input()
↓
OpenAI API 格式(stream=True)
↓
OpenAI API 流式响应
↓
chunk 1 → AIMessage(content="人工") → 打印并累积
chunk 2 → AIMessage(content="智能") → 打印并累积
chunk 3 → AIMessage(content="是...") → 打印并累积
...
↓
full_response = "人工智能是..."
↓
StrOutputParser.parse()
↓
最终输出(字符串)16.3.6 关键设计模式 #
模板方法模式:
BaseOutputParser定义抽象接口StrOutputParser实现具体解析逻辑
工厂模式:
ChatOpenAI._convert_input()将不同格式的输入统一转换为 API 期望的格式
生成器模式:
stream()方法使用yield实现流式输出,节省内存
适配器模式:
StrOutputParser作为适配器,确保输出始终是字符串类型
17.JsonOutputParser #
在用大语言模型(LLM)如 OpenAI 的 GPT 系列进行结构化信息抽取或需要模型输出 JSON 时,经常会碰到以下问题:
- LLM 输出结果不总是 100% 标准 JSON,常出现多余说明、换行、带有 Markdown 代码块等杂质。
- 需要一种健壮的方法能从复杂文本中成功提取纯 JSON 并转为 Python 对象。
- 后续链式处理或数据验证希望输入就是标准的 Python dict 或 list。
JsonOutputParser 便是为这些需求设计的,提供了「宽容但精确」的 JSON 解析能力。
核心功能
- 支持直接 JSON 字符串、Markdown 代码块包裹的 JSON、以及混杂在其它文本中的 JSON。
- 自动清洗和捕获 JSON 主体,异常时给出友好的报错提示。
- 提供给 LLM 使用的格式化指导语(
get_format_instructions),帮助提升 LLM 输出的可用性。
使用流程
- 模型响应处理:
- 假设你 prompt 大模型输出用户信息,通常会写一句:
请严格以 JSON 格式输出,示例:{"name": "张三", "age": 18} - 但 LLM 常常实际输出:
这是您要的信息:json { "name": "李四", "age": 22 } - 直接用
json.loads会失败;用JsonOutputParser能自动解析出来。
- 假设你 prompt 大模型输出用户信息,通常会写一句:
总结
| 方法/属性 | 类型 | 作用 | 典型返回/作用举例 |
|---|---|---|---|
parse(text) |
实例方法 | 解析并返回标准 Python 对象 | dict 或 list |
get_format_instructions() |
实例方法 | 返回一段用于 prompt 的格式严要求例子 | (参见源码及示例) |
parse_json_markdown(text) |
函数 | 辅助函数,提取正文 JSON 内容 | dict 或 list 或抛出异常 |
结构关系图
mermaid
graph TD
UserInput["LLM 原始输出"]
parse_json_markdown["parse_json_markdown()"]
JsonOutputParser["JsonOutputParser.parse()"]
Downstream["结构化 Python 数据(dict/list)"]
UserInput --> JsonOutputParser
JsonOutputParser --> parse_json_markdown
parse_json_markdown --> Downstream17.1. 17.JsonOutputParser.py #
17.JsonOutputParser.py
# 导入自定义的 ChatOpenAI 聊天模型
from smartchain.chat_models import ChatOpenAI
# 导入自定义的提示词模板
from smartchain.prompts import PromptTemplate
# 导入自定义的 Json 输出解析器
from smartchain.output_parsers import JsonOutputParser
# 导入标准库中的 json 模块,用于处理 JSON 数据
import json
# 创建 LLM(大模型)对象,指定使用 "gpt-4o" 模型
llm = ChatOpenAI(model="gpt-4o")
# 创建用于解析 JSON 输出的解析器对象
parser = JsonOutputParser()
# 定义不同测试用的 JSON 格式数据
test_cases = [
# 第一种:纯 JSON 格式的字符串
'{"name": "张三", "age": 25, "city": "北京"}',
# 第二种:包裹在 Markdown 代码块里的 JSON
'``json\n noise {"product": "手机", "price": 3999, "in_stock": true}\n``',
# 第三种:JSON 数组
'["苹果", "香蕉", "橙子"]',
]
# 遍历每个测试用例,解析并输出解析结果
for i, test_input in enumerate(test_cases, 1):
# 使用解析器解析输入字符串
result = parser.parse(test_input)
# 输出解析成功后的结果,以及数据类型
print(f"解析成功:{json.dumps(result, ensure_ascii=False, indent=2)} , {type(result)}")
# 创建提示模板,要求 LLM 按照 JSON 格式输出结构化数据
prompt = PromptTemplate.from_template(
"""你是一个数据提取助手。请从以下文本中提取信息,并以 JSON 格式输出。
文本:{text}
{format_instructions}
请提取以下信息:
- name: 姓名
- age: 年龄
- location: 地点
- interests: 兴趣列表(数组)
JSON 输出:"""
)
# 获取 JSON 格式输出的格式说明
format_instructions = parser.get_format_instructions()
# 输出提示信息,表示即将提取结构化数据
print("\n使用 JsonOutputParser 提取结构化数据:")
# 定义需要提取信息的原始文本列表
test_texts = [
"我叫李四,今年30岁,住在上海。我喜欢编程、阅读和旅行。",
"王五,28岁,来自深圳。爱好包括音乐、电影和摄影。",
]
# 遍历每个测试文本,进行信息提取
for i, text in enumerate(test_texts, 1):
# 根据模板生成提示词,插入原始文本和格式说明
formatted_prompt = prompt.format(
text=text,
format_instructions=format_instructions
)
# 调用大模型,根据提示生成回复
response = llm.invoke(formatted_prompt)
print(response.content)
# 解析模型回复中的 JSON 数据
result = parser.parse(response.content)
# 打印提取到的数据内容
print(f"提取的数据:")
print(json.dumps(result, ensure_ascii=False, indent=2))
# 打印数据的类型名称
print(f"数据类型:{type(result).__name__}")
# 如果解析结果是字典(结构化数据),则访问具体字段并逐项打印
if isinstance(result, dict):
print(f"\n访问数据:")
print(f" 姓名:{result.get('name', 'N/A')}")
print(f" 年龄:{result.get('age', 'N/A')}")
print(f" 地点:{result.get('location', 'N/A')}")
print(f" 兴趣:{result.get('interests', [])}")
17.2. output_parsers.py #
smartchain/output_parsers.py
# 导入抽象类基类(ABC)和抽象方法(abstractmethod)
from abc import ABC, abstractmethod
+import json
+import re
# 定义输出解析器的抽象基类
class BaseOutputParser(ABC):
"""输出解析器的抽象基类"""
# 定义抽象方法 parse,需要子类实现具体的解析逻辑
@abstractmethod
def parse(self, text):
"""
解析输出文本
Args:
text: 要解析的文本
Returns:
解析后的结果
"""
# 抽象方法体,实际不会执行,只是作为接口约束
pass
# 定义字符串输出解析器类,继承自 BaseOutputParser
class StrOutputParser(BaseOutputParser):
"""
字符串输出解析器
将 LLM 的输出解析为字符串。这是最简单的输出解析器,
它不会修改输入内容,只是确保输出是字符串类型。
主要用于:
- 确保 LLM 输出是字符串类型
- 在链式调用中统一输出格式
- 简化输出处理流程
"""
# 实现 parse 方法,将输入内容原样返回为字符串
def parse(self, text: str) -> str:
"""
解析输出文本(实际上只是返回原文本)
Args:
text: 输入文本(应该是字符串)
Returns:
str: 原样返回输入文本
"""
# 如果输入不是字符串,则将其转换为字符串类型
if not isinstance(text, str):
return str(text)
# 如果已经是字符串,则直接返回
return text
# 定义 __repr__ 方法,返回该解析器的字符串表示
def __repr__(self) -> str:
"""返回解析器的字符串表示"""
return "StrOutputParser()"
# 定义一个辅助函数:从文本中提取 JSON(支持 markdown 代码块)
+def parse_json_markdown(text):
+ """
+ 从文本中解析 JSON,支持 markdown 代码块格式
+ Args:
+ text: 可能包含 JSON 的文本
+ Returns:
+ 解析后的 JSON 对象
+ Raises:
+ json.JSONDecodeError: 如果无法解析 JSON
+ """
# 去除 text 字符串首尾的空白字符
+ text = text.strip()
# 正则匹配 markdown 代码块中的 JSON,如 ``json ... `` 或 `` ... ``
+ json_match = re.search(r'```(?:json)?\s*\n?(.*?)\n?```', text, re.DOTALL)
# 如果找到 markdown 代码块匹配
+ if json_match:
# 提取代码块内容并去除首尾空白
+ text = json_match.group(1).strip()
# 再次匹配文本里的 { ... } 或 [ ... ] 结构
+ json_match = re.search(r'(\{.*\}|\ [.*\ ])', text, re.DOTALL)
# 如果找到大括号(对象)或中括号(数组)包裹的 JSON
+ if json_match:
# 提取 JSON 主体内容
+ text = json_match.group(1)
# 用 json.loads 解析 JSON 字符串,返回 Python 对象
+ return json.loads(text)
# 定义一个 JSON 输出解析器类,继承自 BaseOutputParser
+class JsonOutputParser(BaseOutputParser):
+ """
+ JSON 输出解析器
+ 将 LLM 的输出解析为 JSON 对象。支持:
+ - 纯 JSON 字符串
+ - Markdown 代码块中的 JSON(``json ... ``)
+ - 包含 JSON 的文本(自动提取)
+ 主要用于:
+ - 结构化数据提取
+ - API 响应解析
+ - 数据格式化
+ """
# 构造方法,初始化解析器对象
+ def __init__(self):
+ """
+ 初始化 JsonOutputParser
+ """
# 无需特殊初始化操作
+ pass
# 解析输入文本为 JSON 对象
+ def parse(self, text):
+ """
+ 解析 JSON 输出文本
+ Args:
+ text: 包含 JSON 的文本
+ Returns:
+ Any: 解析后的 JSON 对象(字典、列表等)
+ Raises:
+ ValueError: 如果无法解析 JSON
+ """
+ try:
# 使用辅助函数 parse_json_markdown 解析文本内容
+ parsed = parse_json_markdown(text)
# 返回解析结果
+ return parsed
# 捕获 json 格式错误,包装成 ValueError 抛出
+ except json.JSONDecodeError as e:
+ raise ValueError(f"无法解析 JSON 输出: {text[:100]}... 错误: {e}")
# 捕获其他异常,也包装成 ValueError 抛出
+ except Exception as e:
+ raise ValueError(f"解析 JSON 时出错: {e}")
# 返回给 LLM 的 JSON 输出格式要求指导语
+ def get_format_instructions(self) -> str:
+ """
+ 获取格式说明,用于在提示词中指导 LLM 输出 JSON 格式
+ Returns:
+ str: 格式说明文本
+ """
# 返回关于如何格式化 JSON 输出的说明
+ return """请以 JSON 格式输出你的回答。
+ 输出格式要求:
+ 1. 使用有效的 JSON 格式
+ 2. 可以使用 markdown 代码块包裹:``json ... ``
+ 3. 确保所有字符串都用双引号
+ 4. 确保 JSON 格式正确且完整
+ 示例格式:
+ ``json
+ {
+ "key": "value",
+ "number": 123
+ }
+ ``""" 17.3. parse_json_markdown #
17.3.1. 函数定义和文档字符串 #
- 函数名:
parse_json_markdown- 明确表示支持Markdown格式 - 参数:
text- 可能包含JSON的字符串 - 返回: 解析后的Python对象(dict或list)
- 可能抛出的异常:
json.JSONDecodeError- 当JSON格式错误时
17.3.2. 清理输入文本 #
text = text.strip()strip(): 移除字符串首尾的空白字符(空格、制表符、换行符等)- 目的: 确保后续正则匹配不受多余空白的影响
17.3.3. 处理Markdown代码块 #
json_match = re.search(r'``(?:json)?\s*\n?(.*?)\n?``', text, re.DOTALL)- 正则表达式详解:
(?:json)?: 匹配三个反引号开头,json是可选的(?:表示非捕获分组)\s*\n?: 匹配0个或多个空白字符和可选的换行(.*?): 捕获组1 - 匹配任意字符(*?表示非贪婪模式)\n?`: 匹配可选的换行和三个反引号结尾re.DOTALL: 使.也能匹配换行符
- 匹配示例:
json\n{"key": "value"}\n✅\n[1, 2, 3]\n✅json {"key": "value"}✅
if json_match:
text = json_match.group(1).strip()- 条件: 如果找到Markdown代码块
group(1): 获取第一个捕获组的内容(代码块内的文本)- 再次strip: 清理代码块内部的空白
17.3.4. 提取JSON结构 #
json_match = re.search(r'(\{.*\}|\ [.*\ ])', text, re.DOTALL)- 正则表达式详解:
\{.*\}: 匹配以{开头,}结尾的对象$$.*$$: 匹配以[开头,]结尾的数组(\{.*\}|$$.*$$): 捕获分组,匹配上述两种模式之一re.DOTALL: 使.能跨行匹配
- 匹配示例:
{"name": "John", "age": 30}✅["apple", "banana", "orange"]✅- 多行JSON也支持 ✅
if json_match:
text = json_match.group(1)- 条件: 如果找到JSON结构
- 提取: 只保留JSON结构本身,去除周围的其他文本
17.3.5. 解析JSON #
return json.loads(text)- 最终解析: 将处理后的字符串解析为Python对象
- 可能抛出:
json.JSONDecodeError: JSON语法错误TypeError: 输入不是字符串
17.3.6. 使用示例 #
17.3.6.1 场景1: 纯JSON字符串 #
text = '{"name": "Alice", "age": 25}'
result = parse_json_markdown(text) # {'name': 'Alice', 'age': 25}17.3.6.2 场景2: Markdown代码块 #
text = '''
``json
{
"name": "Bob",
"skills": ["Python", "JavaScript"]
}
``
'''
result = parse_json_markdown(text) # {'name': 'Bob', 'skills': [...]}17.3.6.3 场景3: 带额外文本的JSON #
text = '''
输出的结果是:
{"status": "success", "data": {"id": 123}}
请查收。
'''
result = parse_json_markdown(text) # {'status': 'success', ...}17.3.6.4 场景4: 数组JSON #
text = '["item1", "item2", "item3"]'
result = parse_json_markdown(text) # ['item1', 'item2', 'item3']17.4.类 #
17.4.1 类说明 #
| 类名 | 作用 | 主要方法 | 说明 |
|---|---|---|---|
| JsonOutputParser | JSON 输出解析器 | __init__(), parse(), get_format_instructions() |
将 LLM 输出解析为 JSON 对象,支持纯 JSON、Markdown 代码块等多种格式 |
| BaseOutputParser | 输出解析器抽象基类 | parse() (抽象方法) |
定义输出解析器的接口规范 |
| PromptTemplate | 提示词模板类 | __init__(), from_template(), format(), _extract_variables() |
用于创建和格式化提示词模板,支持变量替换 |
| ChatOpenAI | OpenAI 对话模型封装类 | __init__(), invoke(), _convert_input() |
封装 OpenAI API 调用,支持同步调用 |
| AIMessage | AI 消息类 | __init__(), __repr__() |
封装 AI 模型返回的消息内容 |
| BaseMessage | 消息基类 | __init__(), __str__(), __repr__() |
所有消息类型的基类,包含 content 属性 |
JsonOutputParser类
| 方法 | 参数 | 返回值 | 功能描述 |
|---|---|---|---|
__init__() |
无 | 无 | 初始化 JsonOutputParser 实例 |
parse(text) |
text: 包含 JSON 的文本 |
Any (dict/list) |
解析 JSON 输出文本,支持纯 JSON、Markdown 代码块、混合文本等多种格式 |
get_format_instructions() |
无 | str |
返回格式说明文本,用于指导 LLM 输出 JSON 格式 |
PromptTemplate类
| 方法 | 参数 | 返回值 | 功能描述 |
|---|---|---|---|
__init__(template, partial_variables) |
template: 模板字符串partial_variables: 部分变量字典 |
无 | 初始化提示词模板,提取变量名 |
from_template(template) |
template: 模板字符串 |
PromptTemplate |
类方法,从模板字符串创建实例 |
format(**kwargs) |
**kwargs: 变量值 |
str |
填充模板中的变量,返回格式化后的字符串 |
_extract_variables(template) |
template: 模板字符串 |
list[str] |
从模板中提取所有变量名 |
ChatOpenAI类
| 方法 | 参数 | 返回值 | 功能描述 |
|---|---|---|---|
__init__(model, **kwargs) |
model: 模型名称**kwargs: 其他参数 |
无 | 初始化 ChatOpenAI 实例 |
invoke(input, **kwargs) |
input: 输入内容**kwargs: 额外参数 |
AIMessage |
同步调用模型生成完整回复 |
_convert_input(input) |
input: 输入内容 |
list[dict] |
将各种格式的输入转换为 OpenAI API 期望的消息格式 |
辅助函数说明
| 函数名 | 所属模块 | 功能描述 |
|---|---|---|
parse_json_markdown(text) |
smartchain.output_parsers |
从文本中解析 JSON,支持 Markdown 代码块格式,自动提取 JSON 对象或数组 |
17.4.2 类图 #
类关系说明
继承关系:
AIMessage继承自BaseMessageJsonOutputParser继承自BaseOutputParser
依赖关系:
ChatOpenAI.invoke()返回AIMessage对象JsonOutputParser.parse()接收AIMessage.content作为输入JsonOutputParser.parse()内部调用parse_json_markdown()函数PromptTemplate.format()生成的提示词作为ChatOpenAI.invoke()的输入
组合关系:
ChatOpenAI内部包含OpenAI客户端对象PromptTemplate包含模板字符串和变量信息
17.4.3 时序图 #
17.4.3.1 测试用例解析流程 #
17.4.3.2 完整数据提取流程 #
17.4.4 调用过程 #
17.4.4.1 代码执行流程分析 #
阶段一:初始化阶段(第 11-13 行)
llm = ChatOpenAI(model="gpt-4o")
parser = JsonOutputParser()执行过程:
创建
ChatOpenAI实例:- 设置
model = "gpt-4o" - 从环境变量或参数获取
api_key - 初始化 OpenAI 客户端
- 设置
创建
JsonOutputParser实例:- 继承自
BaseOutputParser - 实现
parse()方法用于 JSON 解析 - 提供
get_format_instructions()方法生成格式说明
- 继承自
阶段二:测试用例解析流程(第 26-30 行)
for i, test_input in enumerate(test_cases, 1):
result = parser.parse(test_input)
print(f"解析成功:{json.dumps(result, ensure_ascii=False, indent=2)} , {type(result)}")详细步骤:
调用
parse()方法:输入: test_input (可能是纯 JSON、Markdown 代码块或 JSON 数组) ↓ 调用 parse_json_markdown(text) ↓ 步骤 1: text.strip() - 去除首尾空白 ↓ 步骤 2: 正则匹配 Markdown 代码块 r'```(?:json)?\s*\n?(.*?)\n?```' ↓ 如果找到: 提取代码块内容 ↓ 步骤 3: 正则匹配 JSON 结构 r'(\{.*\}|$$.*$$)' ↓ 如果找到: 提取 JSON 主体 ↓ 步骤 4: json.loads(text) - 解析为 Python 对象 ↓ 返回: dict 或 list错误处理:
- 捕获
json.JSONDecodeError,包装为ValueError - 捕获其他异常,提供友好的错误信息
- 捕获
阶段三:提示词模板创建(第 34-48 行)
prompt = PromptTemplate.from_template(
"""你是一个数据提取助手。请从以下文本中提取信息,并以 JSON 格式输出。
文本:{text}
{format_instructions}
请提取以下信息:
- name: 姓名
- age: 年龄
- location: 地点
- interests: 兴趣列表(数组)
JSON 输出:"""
)执行过程:
from_template()类方法创建实例__init__()调用_extract_variables()提取变量:["text", "format_instructions"]- 设置
input_variables为提取的变量列表
阶段四:格式说明获取(第 51 行)
format_instructions = parser.get_format_instructions()执行过程:
- 返回预定义的 JSON 格式说明文本
- 包含格式要求、示例等内容
- 用于指导 LLM 输出正确的 JSON 格式
阶段五:完整数据提取流程(第 62-87 行)
for i, text in enumerate(test_texts, 1):
formatted_prompt = prompt.format(text=text, format_instructions=format_instructions)
response = llm.invoke(formatted_prompt)
result = parser.parse(response.content)
# ... 打印和访问数据详细步骤:
模板格式化:
prompt.format(text="我叫李四...", format_instructions="请以 JSON 格式输出...") ↓ 检查变量完整性: 确保 text 和 format_instructions 都已提供 ↓ 替换模板变量: {text} → "我叫李四...",{format_instructions} → "请以 JSON 格式输出..." ↓ 返回: 完整的提示词字符串LLM 调用:
llm.invoke(formatted_prompt) ↓ _convert_input() 转换: [{"role": "user", "content": "完整的提示词..."}] ↓ 调用 OpenAI API ↓ 接收响应: response.choices[0].message.content ↓ 返回: AIMessage(content="JSON 格式的回复...")JSON 解析:
parser.parse(response.content) ↓ parse_json_markdown() 处理 ↓ 提取 JSON 对象 ↓ 返回: dict 对象,如 {"name": "李四", "age": 30, ...}数据访问:
result.get('name', 'N/A') # 访问姓名 result.get('age', 'N/A') # 访问年龄 result.get('location', 'N/A') # 访问地点 result.get('interests', []) # 访问兴趣列表
17.4.4.2 数据流转过程 #
完整数据流
原始文本(非结构化)
↓
PromptTemplate.format()
↓
格式化后的提示词(包含格式说明)
↓
ChatOpenAI.invoke()
↓
OpenAI API 调用
↓
AIMessage(content="JSON 格式的回复")
↓
JsonOutputParser.parse()
↓
parse_json_markdown() 处理
↓
提取 JSON 对象
↓
Python dict 对象(结构化数据)
↓
访问字典字段获取具体信息JSON 解析流程
输入文本(可能包含多种格式)
↓
去除首尾空白
↓
正则匹配 Markdown 代码块
↓
[如果找到] 提取代码块内容
↓
正则匹配 JSON 结构 { ... } 或 [ ... ]
↓
[如果找到] 提取 JSON 主体
↓
json.loads() 解析
↓
Python 对象(dict 或 list)17.4.4.3 关键设计模式 #
模板方法模式:
BaseOutputParser定义抽象接口JsonOutputParser实现具体解析逻辑
策略模式:
parse_json_markdown()作为解析策略,支持多种 JSON 格式
模板模式:
PromptTemplate实现提示词模板化,支持变量替换
适配器模式:
JsonOutputParser作为适配器,将各种格式的文本转换为统一的 JSON 对象
工厂模式:
PromptTemplate.from_template()作为工厂方法创建实例
17.4.4.4 JSON 解析能力说明 #
JsonOutputParser 支持以下格式:
纯 JSON 字符串:
{"name": "张三", "age": 25}Markdown 代码块:
```json {"product": "手机", "price": 3999} ```混合文本中的 JSON:
这是前缀文本 {"key": "value"} 这是后缀文本JSON 数组:
["苹果", "香蕉", "橙子"]
18.PydanticOutputParser #
PydanticOutputParser 是一个高级输出解析器,用于将大语言模型(LLM)的输出直接解析为 Pydantic 模型对象,实现输出的结构化、验证和类型安全。
功能概述
与普通的 JSON 解析器不同,PydanticOutputParser 在解析 LLM 返回的 JSON 之后,会进一步自动校验和转换成预定义的 Pydantic 数据模型。这带来了如下优势:
- 自动校验:字段类型、必填/选填项、取值范围等都能严格校验,极大提升下游流程的安全性。
- 数据结构化:产出结果直接是 Pydantic 对象,便于后续调用、属性访问和持续数据处理。
- 自动生成 Schema 指令:可以根据模型,动态返回 LLM Prompt 中用来约束格式的 Schema,提示 LLM 按严格结构输出。
典型应用场景
- 高度结构化的信息抽取, 如实体识别、表格解析、问卷/调查整理等。
- 需要对 LLM 输出结果进行强类型校验和转换的任意场景。
- 与多模型、多步骤链路协同时,保证数据质量和一致性。
工作原理
模型绑定
创建 PydanticOutputParser 时,需将你的 Pydantic 模型类(如Person)传入:person_parser = PydanticOutputParser(pydantic_object=Person)解析流程
- 首先用父类
JsonOutputParser提取、解析出 JSON 字典。 - 然后调用对应 Pydantic 的转换接口:
- 若模型为 Pydantic v2,优先用
.model_validate(json_dict) - 否则用 v1 的
.parse_obj(json_dict) - 再否则使用
Model(**json_dict)(更底层)
- 若模型为 Pydantic v2,优先用
这样可以兼容 Pydantic v1/v2
- 首先用父类
格式要求自动生成
get_format_instructions()会自动据模型生成 LLM Prompts 的格式要求,并自动嵌入 minimal JSON Schema,引导大语言模型按正确格式回复。print(person_parser.get_format_instructions())会输出:
请以 JSON 格式输出,必须严格遵循以下 Schema: ``json { "title": "Person", "type": "object", "properties": { ... } ... } `` 输出要求: 1. 必须完全符合上述 Schema 结构 ...总结
PydanticOutputParser 让 LLM 的结构化信息抽取流程变得极致可靠、安全,也极大促进了 AI 工作流“类型安全、全过程校验”的最佳实践,适合所有需要严肃结构化数据输出的 LLM 应用场景。
18.1. 18.PydanticOutputParser.py #
18.PydanticOutputParser.py
# 导入 PromptTemplate 用于生成用于LLM的提示模板
#from langchain_core.prompts import PromptTemplate
# 导入 PydanticOutputParser,用于将 LLM 的输出解析为 Pydantic 模型
#from langchain_core.output_parsers import PydanticOutputParser
# 导入 ChatOpenAI,构造聊天大模型接口
#from langchain_openai import ChatOpenAI
# 导入 Pydantic 的 BaseModel 和 Field,我们后面定义结构化数据模型
#from pydantic import BaseModel, Field
from smartchain.chat_models import ChatOpenAI
from smartchain.prompts import PromptTemplate
from smartchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
# 导入 smartchain 的 ChatOpenAI,实现统一模型调用接口
from smartchain.chat_models import ChatOpenAI
# 创建 LLM(大语言模型)对象,指定模型为 gpt-4o
llm = ChatOpenAI(model="gpt-4o")
# 定义符合 Pydantic 规范的人员信息模型
class Person(BaseModel):
"""人员信息模型"""
# 姓名,字符串类型
name: str = Field(description="姓名")
# 年龄,整数类型,限定范围为0~150
age: int = Field(description="年龄", ge=0, le=150)
# 邮箱,字符串类型
email: str = Field(description="邮箱地址")
# 城市,字符串类型,默认为“未知”
city: str = Field(description="所在城市", default="未知")
# 创建一个用于将 LLM 输出解析为 Person 模型的解析器
person_parser = PydanticOutputParser(pydantic_object=Person)
# 一个待测试的JSON字符串(模拟 LLM 输出的人员数据)
test_json = '{"name": "张三", "age": 30, "email": "zhangsan@example.com", "city": "北京"}'
# 用解析器将 JSON 字符串解析为 Person 实例
person = person_parser.parse(test_json)
print(person,type(person))
# 构造人员信息抽取的提示模板。{text} 插入原始文本,{format_instructions} 插入格式要求
person_prompt = PromptTemplate.from_template(
"""从以下文本中提取人员信息。
文本:{text}
{format_instructions}
请提取人员信息并以 JSON 格式输出:"""
)
# 构造待提取的原始文本示例(多条)
texts = [
"我叫李四,今年28岁,邮箱是 lisi@example.com,我住在上海。",
"王五,35岁,邮箱地址是 wangwu@test.com,来自深圳。",
]
# 遍历每条原始文本,逐条抽取结构化人员信息
for i, text in enumerate(texts, 1):
# 根据模板和格式要求构造本轮提示词
formatted = person_prompt.format(
text=text,
format_instructions=person_parser.get_format_instructions()
)
print(formatted)
# 将提示词输入 LLM,获得回复
response = llm.invoke(formatted)
# 用 Pydantic 解析器将回复内容解析为 Person 实例
person = person_parser.parse(response.content)
# 打印解析结果
print(f"提取成功!")
print(f" 姓名:{person.name}")
print(f" 年龄:{person.age}")
print(f" 邮箱:{person.email}")
print(f" 城市:{person.city}")
print(f" 类型:{type(person).__name__}")
18.2. output_parsers.py #
smartchain/output_parsers.py
# 导入抽象类基类(ABC)和抽象方法(abstractmethod)
from abc import ABC, abstractmethod
import json
import re
+import pydantic
# 定义输出解析器的抽象基类
class BaseOutputParser(ABC):
"""输出解析器的抽象基类"""
# 定义抽象方法 parse,需要子类实现具体的解析逻辑
@abstractmethod
def parse(self, text):
"""
解析输出文本
Args:
text: 要解析的文本
Returns:
解析后的结果
"""
# 抽象方法体,实际不会执行,只是作为接口约束
pass
# 定义字符串输出解析器类,继承自 BaseOutputParser
class StrOutputParser(BaseOutputParser):
"""
字符串输出解析器
将 LLM 的输出解析为字符串。这是最简单的输出解析器,
它不会修改输入内容,只是确保输出是字符串类型。
主要用于:
- 确保 LLM 输出是字符串类型
- 在链式调用中统一输出格式
- 简化输出处理流程
"""
# 实现 parse 方法,将输入内容原样返回为字符串
def parse(self, text: str) -> str:
"""
解析输出文本(实际上只是返回原文本)
Args:
text: 输入文本(应该是字符串)
Returns:
str: 原样返回输入文本
"""
# 如果输入不是字符串,则将其转换为字符串类型
if not isinstance(text, str):
return str(text)
# 如果已经是字符串,则直接返回
return text
# 定义 __repr__ 方法,返回该解析器的字符串表示
def __repr__(self) -> str:
"""返回解析器的字符串表示"""
return "StrOutputParser()"
# 定义一个辅助函数:从文本中提取 JSON(支持 markdown 代码块)
def parse_json_markdown(text):
"""
从文本中解析 JSON,支持 markdown 代码块格式
Args:
text: 可能包含 JSON 的文本
Returns:
解析后的 JSON 对象
Raises:
json.JSONDecodeError: 如果无法解析 JSON
"""
# 去除 text 字符串首尾的空白字符
text = text.strip()
# 正则匹配 markdown 代码块中的 JSON,如 ``json ... `` 或 `` ... ``
json_match = re.search(r'``(?:json)?\s*\n?(.*?)\n?``', text, re.DOTALL)
# 如果找到 markdown 代码块匹配
if json_match:
# 提取代码块内容并去除首尾空白
text = json_match.group(1).strip()
# 再次匹配文本里的 { ... } 或 [ ... ] 结构
json_match = re.search(r'(\{.*\}|$$.*$$)', text, re.DOTALL)
# 如果找到大括号(对象)或中括号(数组)包裹的 JSON
if json_match:
# 提取 JSON 主体内容
text = json_match.group(1)
# 用 json.loads 解析 JSON 字符串,返回 Python 对象
return json.loads(text)
# 定义一个 JSON 输出解析器类,继承自 BaseOutputParser
class JsonOutputParser(BaseOutputParser):
"""
JSON 输出解析器
将 LLM 的输出解析为 JSON 对象。支持:
- 纯 JSON 字符串
- Markdown 代码块中的 JSON(``json ... ``)
- 包含 JSON 的文本(自动提取)
主要用于:
- 结构化数据提取
- API 响应解析
- 数据格式化
"""
# 构造方法,初始化解析器对象
def __init__(self):
"""
初始化 JsonOutputParser
"""
pass
# 解析输入文本为 JSON 对象
def parse(self, text):
"""
解析 JSON 输出文本
Args:
text: 包含 JSON 的文本
Returns:
Any: 解析后的 JSON 对象(字典、列表等)
Raises:
ValueError: 如果无法解析 JSON
"""
try:
# 使用辅助函数 parse_json_markdown 解析文本内容
parsed = parse_json_markdown(text)
# 返回解析结果
return parsed
# 捕获 json 格式错误,包装成 ValueError 抛出
except json.JSONDecodeError as e:
raise ValueError(f"无法解析 JSON 输出: {text[:100]}... 错误: {e}")
# 捕获其他异常,也包装成 ValueError 抛出
except Exception as e:
raise ValueError(f"解析 JSON 时出错: {e}")
# 返回给 LLM 的 JSON 输出格式要求指导语
def get_format_instructions(self) -> str:
"""
获取格式说明,用于在提示词中指导 LLM 输出 JSON 格式
Returns:
str: 格式说明文本
"""
# 返回关于如何格式化 JSON 输出的说明
return """请以 JSON 格式输出你的回答。
输出格式要求:
1. 使用有效的 JSON 格式
2. 可以使用 markdown 代码块包裹:``json ... ``
3. 确保所有字符串都用双引号
4. 确保 JSON 格式正确且完整
示例格式:
``json
{
"key": "value",
"number": 123
}
``"""
# 定义 Pydantic 输出解析器类,继承自 JsonOutputParser
+class PydanticOutputParser(JsonOutputParser):
# 用于 Pydantic 输出解析器的类注释
+ """
+ Pydantic 输出解析器
+ 将 LLM 的输出解析为 Pydantic 模型实例。继承自 JsonOutputParser,
+ 先解析 JSON,然后验证并转换为 Pydantic 模型。
+ 主要用于:
+ - 结构化数据验证
+ - 类型安全的数据提取
+ - 自动数据验证和转换
+ """
# 构造函数,初始化 PydanticOutputParser
+ def __init__(self, pydantic_object: type):
# 调用父类 JsonOutputParser 的构造方法
+ super().__init__()
# 保存用户传入的 Pydantic 模型类
+ self.pydantic_object = pydantic_object
# 解析函数,将文本解析为 Pydantic 实例
+ def parse(self, text: str):
# 尝试解析并转换文本为 Pydantic 实例
+ try:
# 首先用父类方法将文本解析为 JSON 对象(如 dict)
+ json_obj = super().parse(text)
# 将 JSON 对象转为 Pydantic 模型实例
+ return self._parse_obj(json_obj)
# 捕获并包装所有异常为 ValueError
+ except Exception as e:
+ raise ValueError(f"无法解析为 Pydantic 模型: {e}")
# 辅助方法:将字典对象转换为 Pydantic 模型实例
+ def _parse_obj(self, obj: dict):
# 如果模型有 model_validate 方法(Pydantic v2),优先使用
+ if hasattr(self.pydantic_object, 'model_validate'):
+ return self.pydantic_object.model_validate(obj)
# 如果模型有 parse_obj 方法(Pydantic v1),则使用
+ elif hasattr(self.pydantic_object, 'parse_obj'):
+ return self.pydantic_object.parse_obj(obj)
# 否则,尝试直接用 ** 解包初始化
+ else:
+ return self.pydantic_object(**obj)
# 私有方法,获取 Pydantic 模型的 JSON Schema
+ def _get_schema(self) -> dict:
# 尝试获取 schema,支持 Pydantic v1 和 v2
+ try:
# v2: 使用 model_json_schema 方法
+ if hasattr(self.pydantic_object, 'model_json_schema'):
+ return self.pydantic_object.model_json_schema()
# v1: 使用 schema 方法
+ elif hasattr(self.pydantic_object, 'schema'):
+ return self.pydantic_object.schema()
# 如果都没有则返回空字典
+ else:
+ return {}
# 捕获异常并返回空字典
+ except Exception:
+ return {}
# 返回格式说明,自动添加 schema 信息
+ def get_format_instructions(self) -> str:
# 获取 Pydantic 模型 schema
+ schema = self._get_schema()
# 拷贝一份 schema 进行编辑
+ reduced_schema = dict(schema)
# 删除 description 字段(如果有)
+ if "description" in reduced_schema:
+ del reduced_schema["description"]
# 序列化 schema 为格式化字符串
+ schema_str = json.dumps(reduced_schema, ensure_ascii=False, indent=2)
# 返回格式说明字符串,内嵌 JSON Schema
+ return f"""请以 JSON 格式输出,必须严格遵循以下 Schema:
+ ``json
+ {schema_str}
+ ``
+ 输出要求:
+ 1. 必须完全符合上述 Schema 结构
+ 2. 所有必需字段都必须提供
+ 3. 字段类型必须匹配(字符串、数字、布尔值等)
+ 4. 使用有效的 JSON 格式
+ 5. 可以使用 markdown 代码块包裹:``json ... ``
+ 确保输出是有效的 JSON,并且符合 Schema 定义。"""
18.3. 模型解析 #
# 辅助方法:将字典对象转换为 Pydantic 模型实例
def _parse_obj(self, obj: dict):
# 如果模型有 model_validate 方法(Pydantic v2),优先使用
if hasattr(self.pydantic_object, 'model_validate'):
return self.pydantic_object.model_validate(obj)
# 如果模型有 parse_obj 方法(Pydantic v1),则使用
elif hasattr(self.pydantic_object, 'parse_obj'):
return self.pydantic_object.parse_obj(obj)
# 否则,尝试直接用 ** 解包初始化
else:
return self.pydantic_object(**obj)这个方法的目的是:安全地将字典对象转换为 Pydantic 模型实例,同时兼容所有可能的 Pydantic 版本和配置。
18.3.1. 方法签名和设计理念 #
def _parse_obj(self, obj: dict):- 命名:
_parse_obj表明这是内部辅助方法(单下划线约定) - 参数:
obj: dict- 必须是字典类型,是 JSON 解析后的 Python 对象 - 返回:Pydantic 模型实例
18.3.2. 优先级解析策略(三级回退) #
18.3.2.1 第一级:Pydantic v2 (2023年6月+) #
if hasattr(self.pydantic_object, 'model_validate'):
return self.pydantic_object.model_validate(obj)- 检查方法:
hasattr()动态检查是否存在属性 - model_validate():Pydantic v2 的推荐验证方法
- 特点:
- 性能优化(快 5-50 倍)
- 更好的错误信息
- 支持更复杂的验证逻辑
- 完全类型安全
18.3.2.2 第二级:Pydantic v1 (2019-2023) #
elif hasattr(self.pydantic_object, 'parse_obj'):
return self.pydantic_object.parse_obj(obj)- parse_obj():Pydantic v1 的标准验证方法
- 向后兼容:确保老项目能继续工作
- 功能:基本验证和类型转换
18.3.2.3 第三级:降级方案(最保险的方式) #
else:
return self.pydantic_object(**obj)- 直接初始化:使用 Python 的
**解包操作符 - 适用场景:
- 自定义的类(不是严格意义上的 Pydantic 模型)
- 极简配置的 Pydantic 模型
- 兼容性最强,但不提供验证
18.4. 类 #
18.4.1 类说明 #
| 类名 | 作用 | 主要方法 | 说明 |
|---|---|---|---|
| PydanticOutputParser | Pydantic 输出解析器 | __init__(), parse(), get_format_instructions(), _parse_obj(), _get_schema() |
将 LLM 输出解析为 Pydantic 模型实例,支持数据验证和类型转换 |
| JsonOutputParser | JSON 输出解析器(父类) | parse(), get_format_instructions() |
提供 JSON 解析基础功能,支持多种 JSON 格式 |
| BaseOutputParser | 输出解析器抽象基类 | parse() (抽象方法) |
定义输出解析器的接口规范 |
| PromptTemplate | 提示词模板类 | __init__(), from_template(), format(), _extract_variables() |
用于创建和格式化提示词模板,支持变量替换 |
| ChatOpenAI | OpenAI 对话模型封装类 | __init__(), invoke(), _convert_input() |
封装 OpenAI API 调用,支持同步调用 |
| AIMessage | AI 消息类 | __init__(), __repr__() |
封装 AI 模型返回的消息内容 |
| BaseModel | Pydantic 模型基类 | model_validate(), parse_obj(), schema(), model_json_schema() |
提供数据验证和序列化功能 |
PydanticOutputParser类
| 方法 | 参数 | 返回值 | 功能描述 |
|---|---|---|---|
__init__(pydantic_object) |
pydantic_object: Pydantic 模型类 |
无 | 初始化解析器,保存目标 Pydantic 模型类 |
parse(text) |
text: 包含 JSON 的文本 |
Pydantic 模型实例 |
解析文本为 JSON,然后转换为 Pydantic 模型实例 |
get_format_instructions() |
无 | str |
返回包含 JSON Schema 的格式说明,指导 LLM 输出符合 Schema 的 JSON |
_parse_obj(obj) |
obj: 字典对象 |
Pydantic 模型实例 |
将字典转换为 Pydantic 模型实例,支持 v1 和 v2 |
_get_schema() |
无 | dict |
获取 Pydantic 模型的 JSON Schema,支持 v1 和 v2 |
Person 模型(用户定义)
| 字段 | 类型 | 约束 | 说明 |
|---|---|---|---|
name |
str |
必需 | 姓名 |
age |
int |
必需,范围 0-150 | 年龄 |
email |
str |
必需 | 邮箱地址 |
city |
str |
可选,默认 "未知" | 所在城市 |
辅助函数说明
| 函数名 | 所属模块 | 功能描述 |
|---|---|---|
parse_json_markdown(text) |
smartchain.output_parsers |
从文本中解析 JSON,支持 Markdown 代码块格式,自动提取 JSON 对象或数组 |
18.4.2 类图 #
类关系说明
继承关系:
AIMessage继承自BaseMessageJsonOutputParser继承自BaseOutputParserPydanticOutputParser继承自JsonOutputParser(多层继承)Person继承自BaseModel(Pydantic)
依赖关系:
ChatOpenAI.invoke()返回AIMessage对象PydanticOutputParser.parse()接收AIMessage.content作为输入PydanticOutputParser通过父类JsonOutputParser间接调用parse_json_markdown()PydanticOutputParser._parse_obj()使用BaseModel的方法创建实例PromptTemplate.format()生成的提示词作为ChatOpenAI.invoke()的输入
组合关系:
ChatOpenAI内部包含OpenAI客户端对象PromptTemplate包含模板字符串和变量信息PydanticOutputParser包含pydantic_object类型引用
18.4.3 时序图 #
18.4.3.1 测试用例解析流程 #
18.4.3.2 完整数据提取流程 #
18.4.4 调用过程 #
18.4.4.1 代码执行流程 #
阶段一:模型定义(第 23-32 行)
class Person(BaseModel):
name: str = Field(description="姓名")
age: int = Field(description="年龄", ge=0, le=150)
email: str = Field(description="邮箱地址")
city: str = Field(description="所在城市", default="未知")执行过程:
- 定义
Person类继承自BaseModel - 定义字段及类型约束:
name: 字符串类型,必需age: 整数类型,必需,范围 0-150email: 字符串类型,必需city: 字符串类型,可选,默认值 "未知"
- Pydantic 自动生成验证逻辑和 JSON Schema
阶段二:初始化阶段(第 20、35 行)
llm = ChatOpenAI(model="gpt-4o")
person_parser = PydanticOutputParser(pydantic_object=Person)执行过程:
创建
ChatOpenAI实例:- 设置
model = "gpt-4o" - 初始化 OpenAI 客户端
- 设置
创建
PydanticOutputParser实例:PydanticOutputParser.__init__(Person) ↓ 调用 super().__init__() - JsonOutputParser.__init__() ↓ 保存 self.pydantic_object = Person
阶段三:测试用例解析(第 40-42 行)
test_json = '{"name": "张三", "age": 30, "email": "zhangsan@example.com", "city": "北京"}'
person = person_parser.parse(test_json)详细步骤:
调用
parse()方法:输入: test_json (JSON 字符串) ↓ PydanticOutputParser.parse(test_json) ↓ 步骤 1: super().parse(text) - 调用父类 JsonOutputParser.parse() ↓ 步骤 2: parse_json_markdown(text) - 提取并解析 JSON ↓ 步骤 3: json.loads() - 转换为 Python dict ↓ 返回: json_obj = {"name": "张三", "age": 30, ...} ↓ 步骤 4: _parse_obj(json_obj) - 转换为 Pydantic 模型 ↓ 步骤 5: Person.model_validate(json_obj) - 验证并创建实例 ↓ Pydantic 验证: - 检查字段类型(name 是 str,age 是 int) - 检查约束(age 在 0-150 范围内) - 应用默认值(city 如果缺失则使用 "未知") ↓ 返回: Person 实例Pydantic 验证过程:
- 类型验证:确保
age是整数 - 约束验证:确保
age在 0-150 范围内 - 默认值应用:如果
city缺失,使用 "未知" - 如果验证失败,抛出
ValidationError
- 类型验证:确保
阶段四:提示词模板创建(第 45-53 行)
person_prompt = PromptTemplate.from_template(
"""从以下文本中提取人员信息。
文本:{text}
{format_instructions}
请提取人员信息并以 JSON 格式输出:"""
)执行过程:
from_template()创建实例_extract_variables()提取变量:["text", "format_instructions"]- 设置
input_variables为提取的变量列表
阶段五:格式说明获取(第 66 行)
format_instructions = person_parser.get_format_instructions()详细步骤:
get_format_instructions()
↓
步骤 1: _get_schema() - 获取 Person 模型的 JSON Schema
↓
尝试 Person.model_json_schema() (Pydantic v2)
或 Person.schema() (Pydantic v1)
↓
返回: {
"type": "object",
"properties": {
"name": {"type": "string", "description": "姓名"},
"age": {"type": "integer", "minimum": 0, "maximum": 150},
"email": {"type": "string"},
"city": {"type": "string", "default": "未知"}
},
"required": ["name", "age", "email"]
}
↓
步骤 2: 删除 "description" 字段(如果存在)
↓
步骤 3: json.dumps(schema, indent=2) - 格式化为字符串
↓
步骤 4: 生成格式说明文本,包含 Schema 和输出要求
↓
返回: "请以 JSON 格式输出,必须严格遵循以下 Schema:..."阶段六:完整数据提取流程(第 62-82 行)
for i, text in enumerate(texts, 1):
formatted = person_prompt.format(
text=text,
format_instructions=person_parser.get_format_instructions()
)
response = llm.invoke(formatted)
person = person_parser.parse(response.content)
# ... 访问字段详细步骤:
模板格式化:
prompt.format(text="我叫李四...", format_instructions="请以 JSON 格式输出...") ↓ 检查变量完整性 ↓ 替换变量: {text} → "我叫李四,今年28岁..." {format_instructions} → "请以 JSON 格式输出,必须严格遵循以下 Schema:..." ↓ 返回: 完整的提示词字符串(包含 JSON Schema)LLM 调用:
llm.invoke(formatted) ↓ _convert_input() 转换输入格式 ↓ 调用 OpenAI API ↓ 接收响应: JSON 格式的回复 ↓ 返回: AIMessage(content="JSON 字符串")Pydantic 解析:
parser.parse(response.content) ↓ 步骤 1: super().parse() - 解析 JSON 字符串为 dict ↓ 步骤 2: _parse_obj(dict) - 转换为 Person 实例 ↓ 步骤 3: Person.model_validate(dict) ↓ Pydantic 验证: - 类型检查: name 必须是 str, age 必须是 int - 约束检查: age 必须在 0-150 范围内 - 必需字段检查: name, age, email 必须存在 - 默认值应用: city 如果缺失则使用 "未知" ↓ 如果验证通过: 返回 Person 实例 如果验证失败: 抛出 ValidationError ↓ 返回: Person 对象数据访问:
person.name # 访问姓名(str) person.age # 访问年龄(int,已验证范围) person.email # 访问邮箱(str) person.city # 访问城市(str,可能有默认值)
18.4.4.2 数据流转过程 #
完整数据流
原始文本(非结构化)
↓
PromptTemplate.format()
↓
格式化后的提示词(包含 JSON Schema)
↓
ChatOpenAI.invoke()
↓
OpenAI API 调用
↓
AIMessage(content="JSON 格式的回复")
↓
PydanticOutputParser.parse()
↓
步骤 1: JsonOutputParser.parse() - 解析 JSON
↓
parse_json_markdown() 处理
↓
提取 JSON 对象 → Python dict
↓
步骤 2: _parse_obj() - 转换为 Pydantic 模型
↓
Person.model_validate(dict)
↓
Pydantic 验证和转换
↓
Person 实例(类型安全的结构化数据)
↓
访问对象属性获取具体信息Pydantic 验证流程
JSON 对象(dict)
↓
Person.model_validate(dict)
↓
字段验证:
- name: str 类型检查
- age: int 类型检查 + 范围检查 (0-150)
- email: str 类型检查
- city: str 类型检查(可选,默认 "未知")
↓
必需字段检查: name, age, email 必须存在
↓
类型转换: 确保所有字段类型正确
↓
创建 Person 实例
↓
返回: Person 对象(带类型提示和验证)18.4.4.3 关键设计模式 #
模板方法模式:
BaseOutputParser定义抽象接口JsonOutputParser实现 JSON 解析PydanticOutputParser扩展为 Pydantic 模型解析
继承模式:
PydanticOutputParser继承JsonOutputParser,复用 JSON 解析逻辑- 通过
super().parse()调用父类方法
适配器模式:
PydanticOutputParser作为适配器,将 JSON 对象适配为 Pydantic 模型
策略模式:
_parse_obj()支持多种 Pydantic 版本(v1/v2)的解析策略
模板模式:
PromptTemplate实现提示词模板化get_format_instructions()动态生成包含 Schema 的格式说明
18.4.4..4 Pydantic 版本兼容性 #
PydanticOutputParser 支持 Pydantic v1 和 v2:
Pydantic v2:
- 使用
model_validate()方法 - 使用
model_json_schema()获取 Schema
- 使用
Pydantic v1:
- 使用
parse_obj()方法 - 使用
schema()获取 Schema
- 使用
降级策略:
- 如果都不支持,尝试直接使用
**obj解包初始化
- 如果都不支持,尝试直接使用
18.4.4.5 数据验证优势 #
相比 JsonOutputParser,PydanticOutputParser 提供:
类型安全:
- 自动类型检查和转换
- IDE 支持类型提示和自动补全
数据验证:
- 字段约束验证(如 age 范围)
- 必需字段检查
- 默认值自动应用
结构化访问:
- 使用
person.name而不是result['name'] - 更清晰的代码和更好的可读性
- 使用
错误处理:
- 详细的验证错误信息
- 明确指出哪个字段验证失败
19.OutputFixingParser #
设计动机
大语言模型(LLM)有时会⽣成格式错误的输出。例如,本应返回严格的 JSON,但却遗漏了引号、加了多余逗号,或包含注释等非法内容。这时,传统的解析器(如 json.loads)就会抛出异常。但很多场景下,我们并不希望模型因格式小错误而报错终止,而是能自动修复这些格式问题,再次解析。
OutputFixingParser 正是为此设计的——它 “套娃” 了一个解析器,每当解析失败时,会自动调用 LLM 生成格式正确的新输出,并自动重试解析,最多尝试若干次。这大幅提升了 LLM 结果的健壮性,减少了人工干预。
类原理图
用户输入
│
▼
[OutputFixingParser]
│
├─(尝试 .parse)─> [基础解析器]
│ │
│ (失败)
▼
[调用 LLM 补救链:传递格式说明、原始输出、报错信息]
│
▼
[获得修复后的输出]──> 再次 .parse
│
...
[最多 N 次重试]使用方式
from smartchain.chat_models import ChatOpenAI
from smartchain.output_parsers import JsonOutputParser, OutputFixingParser
llm = ChatOpenAI(model="gpt-4o")
json_parser = JsonOutputParser()
fixing_parser = OutputFixingParser.from_llm(llm, json_parser, max_retries=2)
# 调用自动修复解析器(自动多次尝试)
obj = fixing_parser.parse('{"name": "张三" "age": 30}') # 缺逗号的 JSON- 若基础解析器失败,则自动触发 LLM 修复一次并重试解析
max_retries设置最大修正次数
方法说明
from_llm: 工厂方法,组合 LLM、基础解析器,自动构造补救链parse: 尝试解析→失败就 LLM 补救→成功或重试到上限报错get_format_instructions: 返回格式要求,通常委托给基础解析器- 支持自定义修复的 Prompt,可以适配各种结构化输出需求
典型应用场景
- LLM 数据抽取、结构化生成、信息解析(如 LangChain/Cognitive Search)
- 任何对输出格式严要求但 LLM 偶发“疏漏”的情况
- “无痕”补救,不惊动应用端
小贴士:
- OutputFixingParser 让你的结构化解析 “有保险”!
- 配合自定义
prompt,还可适配 YAML/Markdown/表格等格式修复。
19.1. 19.OutputFixingParser.py #
19.OutputFixingParser.py
#from langchain_core.prompts import PromptTemplate
#from langchain_core.output_parsers import JsonOutputParser, PydanticOutputParser
#from langchain_classic.output_parsers.fix import OutputFixingParser
#from langchain_openai import ChatOpenAI
# 导入所需的 json 模块
import json
# 从 smartchain.chat_models 导入 ChatOpenAI 模型
from smartchain.chat_models import ChatOpenAI
# 从 smartchain.output_parsers 导入 JsonOutputParser 和 OutputFixingParser
from smartchain.output_parsers import JsonOutputParser, OutputFixingParser
# 创建一个 LLM(大语言模型)实例,这里选用 gpt-4o 模型
llm = ChatOpenAI(model="gpt-4o")
# 创建一个基础的 JSON 解析器实例
json_parser = JsonOutputParser()
# 使用 LLM 和基础解析器创建一个输出修复解析器,并设置最大重试次数为 2 次
fixing_parser = OutputFixingParser.from_llm(
llm=llm,
parser=json_parser,
max_retries=2,
)
# 构造一组无效的 JSON 字符串用于测试
invalid_outputs = [
# 缺少引号的 JSON
'{name: "张三", age: 30, city: "北京"}',
# 使用单引号,JSON 只能使用双引号
"{'product': '手机', 'price': 3999}",
# 缺少逗号分隔的 JSON
'{"name": "李四" "age": 25}',
# 包含注释,JSON 格式不支持注释
'{"name": "王五", /* 这是注释 */ "age": 28}',
]
# 遍历所有无效的 JSON 测试用例
for i, invalid_output in enumerate(invalid_outputs, 1):
try:
try:
# 尝试用基础 JSON 解析器解析
result = json_parser.parse(invalid_output)
# 如果解析成功(实际应当失败)则输出提示
print(f"基础解析器:解析成功(意外)")
except Exception as e:
# 如果解析失败,输出失败信息和错误类型
print(f"基础解析器:解析失败 ✓")
print(f" 错误:{type(e).__name__}: {e}")
# 输出消息,表示开始使用 OutputFixingParser 进行修复
print("\n使用 OutputFixingParser:")
print(" 正在使用 LLM 修复输出...")
try:
# 用输出修复解析器尝试修正并解析无效 JSON
result = fixing_parser.parse(invalid_output)
# 修复成功后输出修复结果
print(f" 修复后解析成功!")
print(f" 结果:{json.dumps(result, ensure_ascii=False, indent=2)}")
except Exception as e:
# 如果修复后依然解析失败,输出错误信息
print(f" 修复失败:{type(e).__name__}: {e}")
except Exception as e:
# 捕获所有异常,防止程序中断,并输出异常信息
print(f"修复失败:{e}")
19.2. output_parsers.py #
smartchain/output_parsers.py
# 导入抽象类基类(ABC)和抽象方法(abstractmethod)
from abc import ABC, abstractmethod
import json
import re
import pydantic
+from .prompts import PromptTemplate
# 定义输出解析器的抽象基类
class BaseOutputParser(ABC):
"""输出解析器的抽象基类"""
# 定义抽象方法 parse,需要子类实现具体的解析逻辑
@abstractmethod
def parse(self, text):
"""
解析输出文本
Args:
text: 要解析的文本
Returns:
解析后的结果
"""
# 抽象方法体,实际不会执行,只是作为接口约束
pass
# 定义字符串输出解析器类,继承自 BaseOutputParser
class StrOutputParser(BaseOutputParser):
"""
字符串输出解析器
将 LLM 的输出解析为字符串。这是最简单的输出解析器,
它不会修改输入内容,只是确保输出是字符串类型。
主要用于:
- 确保 LLM 输出是字符串类型
- 在链式调用中统一输出格式
- 简化输出处理流程
"""
# 实现 parse 方法,将输入内容原样返回为字符串
def parse(self, text: str) -> str:
"""
解析输出文本(实际上只是返回原文本)
Args:
text: 输入文本(应该是字符串)
Returns:
str: 原样返回输入文本
"""
# 如果输入不是字符串,则将其转换为字符串类型
if not isinstance(text, str):
return str(text)
# 如果已经是字符串,则直接返回
return text
# 定义 __repr__ 方法,返回该解析器的字符串表示
def __repr__(self) -> str:
"""返回解析器的字符串表示"""
return "StrOutputParser()"
# 定义一个辅助函数:从文本中提取 JSON(支持 markdown 代码块)
def parse_json_markdown(text):
"""
从文本中解析 JSON,支持 markdown 代码块格式
Args:
text: 可能包含 JSON 的文本
Returns:
解析后的 JSON 对象
Raises:
json.JSONDecodeError: 如果无法解析 JSON
"""
# 去除 text 字符串首尾的空白字符
text = text.strip()
# 正则匹配 markdown 代码块中的 JSON,如 ``json ... `` 或 `` ... ``
json_match = re.search(r'``(?:json)?\s*\n?(.*?)\n?``', text, re.DOTALL)
# 如果找到 markdown 代码块匹配
if json_match:
# 提取代码块内容并去除首尾空白
text = json_match.group(1).strip()
# 再次匹配文本里的 { ... } 或 [ ... ] 结构
json_match = re.search(r'(\{.*\}|$$.*$$)', text, re.DOTALL)
# 如果找到大括号(对象)或中括号(数组)包裹的 JSON
if json_match:
# 提取 JSON 主体内容
text = json_match.group(1)
# 用 json.loads 解析 JSON 字符串,返回 Python 对象
return json.loads(text)
# 定义一个 JSON 输出解析器类,继承自 BaseOutputParser
class JsonOutputParser(BaseOutputParser):
"""
JSON 输出解析器
将 LLM 的输出解析为 JSON 对象。支持:
- 纯 JSON 字符串
- Markdown 代码块中的 JSON(``json ... ``)
- 包含 JSON 的文本(自动提取)
主要用于:
- 结构化数据提取
- API 响应解析
- 数据格式化
"""
# 构造方法,初始化解析器对象
def __init__(self):
"""
初始化 JsonOutputParser
"""
pass
# 解析输入文本为 JSON 对象
def parse(self, text):
"""
解析 JSON 输出文本
Args:
text: 包含 JSON 的文本
Returns:
Any: 解析后的 JSON 对象(字典、列表等)
Raises:
ValueError: 如果无法解析 JSON
"""
try:
# 使用辅助函数 parse_json_markdown 解析文本内容
parsed = parse_json_markdown(text)
# 返回解析结果
return parsed
# 捕获 json 格式错误,包装成 ValueError 抛出
except json.JSONDecodeError as e:
raise ValueError(f"无法解析 JSON 输出: {text[:100]}... 错误: {e}")
# 捕获其他异常,也包装成 ValueError 抛出
except Exception as e:
raise ValueError(f"解析 JSON 时出错: {e}")
# 返回给 LLM 的 JSON 输出格式要求指导语
def get_format_instructions(self) -> str:
"""
获取格式说明,用于在提示词中指导 LLM 输出 JSON 格式
Returns:
str: 格式说明文本
"""
# 返回关于如何格式化 JSON 输出的说明
return """请以 JSON 格式输出你的回答。
输出格式要求:
1. 使用有效的 JSON 格式
2. 可以使用 markdown 代码块包裹:``json ... ``
3. 确保所有字符串都用双引号
4. 确保 JSON 格式正确且完整
示例格式:
``json
{
"key": "value",
"number": 123
}
``"""
# 定义 Pydantic 输出解析器类,继承自 JsonOutputParser
class PydanticOutputParser(JsonOutputParser):
# 用于 Pydantic 输出解析器的类注释
"""
Pydantic 输出解析器
将 LLM 的输出解析为 Pydantic 模型实例。继承自 JsonOutputParser,
先解析 JSON,然后验证并转换为 Pydantic 模型。
主要用于:
- 结构化数据验证
- 类型安全的数据提取
- 自动数据验证和转换
"""
# 构造函数,初始化 PydanticOutputParser
def __init__(self, pydantic_object: type):
# 调用父类 JsonOutputParser 的构造方法
super().__init__()
# 保存用户传入的 Pydantic 模型类
self.pydantic_object = pydantic_object
# 解析函数,将文本解析为 Pydantic 实例
def parse(self, text: str):
# 尝试解析并转换文本为 Pydantic 实例
try:
# 首先用父类方法将文本解析为 JSON 对象(如 dict)
json_obj = super().parse(text)
# 将 JSON 对象转为 Pydantic 模型实例
return self._parse_obj(json_obj)
# 捕获并包装所有异常为 ValueError
except Exception as e:
raise ValueError(f"无法解析为 Pydantic 模型: {e}")
# 辅助方法:将字典对象转换为 Pydantic 模型实例
def _parse_obj(self, obj: dict):
# 如果模型有 model_validate 方法(Pydantic v2),优先使用
if hasattr(self.pydantic_object, 'model_validate'):
return self.pydantic_object.model_validate(obj)
# 如果模型有 parse_obj 方法(Pydantic v1),则使用
elif hasattr(self.pydantic_object, 'parse_obj'):
return self.pydantic_object.parse_obj(obj)
# 否则,尝试直接用 ** 解包初始化
else:
return self.pydantic_object(**obj)
# 私有方法,获取 Pydantic 模型的 JSON Schema
def _get_schema(self) -> dict:
# 尝试获取 schema,支持 Pydantic v1 和 v2
try:
# v2: 使用 model_json_schema 方法
if hasattr(self.pydantic_object, 'model_json_schema'):
return self.pydantic_object.model_json_schema()
# v1: 使用 schema 方法
elif hasattr(self.pydantic_object, 'schema'):
return self.pydantic_object.schema()
# 如果都没有则返回空字典
else:
return {}
# 捕获异常并返回空字典
except Exception:
return {}
# 返回格式说明,自动添加 schema 信息
def get_format_instructions(self) -> str:
# 获取 Pydantic 模型 schema
schema = self._get_schema()
# 拷贝一份 schema 进行编辑
reduced_schema = dict(schema)
# 删除 description 字段(如果有)
if "description" in reduced_schema:
del reduced_schema["description"]
# 序列化 schema 为格式化字符串
schema_str = json.dumps(reduced_schema, ensure_ascii=False, indent=2)
# 返回格式说明字符串,内嵌 JSON Schema
return f"""请以 JSON 格式输出,必须严格遵循以下 Schema:
``json
{schema_str}
``
输出要求:
1. 必须完全符合上述 Schema 结构
2. 所有必需字段都必须提供
3. 字段类型必须匹配(字符串、数字、布尔值等)
4. 使用有效的 JSON 格式
5. 可以使用 markdown 代码块包裹:``json ... ``
确保输出是有效的 JSON,并且符合 Schema 定义。"""
# 简单的链式调用包装类
+class SimpleChain:
# 初始化方法,保存 prompt、llm 和 parser
+ def __init__(self, prompt, llm, parser):
+ self.prompt = prompt
+ self.llm = llm
+ self.parser = parser
# 调用链方法,接收输入字典,返回字符串
+ def invoke(self, input_dict: dict) -> str:
# 格式化提示词
+ formatted = self.prompt.format(**input_dict)
# 通过 llm 调用生成响应
+ response = self.llm.invoke(formatted)
# 判断响应是否有 content 属性
+ if hasattr(response, 'content'):
+ content = response.content
+ else:
# 若无 content 属性,则转换为字符串
+ content = str(response)
# 使用 parser 解析内容
+ return self.parser.parse(content)
# 兼容旧接口的运行方法
+ def run(self, **kwargs) -> str:
# 调用 invoke 方法,传入参数
+ return self.invoke(kwargs)
# 输出解析异常类,继承自 ValueError
+class OutputParserException(ValueError):
# 初始化方法,保存异常信息和 llm 输出
+ def __init__(self, message: str, llm_output: str = ""):
+ super().__init__(message)
+ self.llm_output = llm_output
# 输出修复解析器类,继承自 BaseOutputParser
+class OutputFixingParser(BaseOutputParser):
+ """
+ 输出修复解析器
+ 包装一个基础解析器,当解析失败时,使用 LLM 自动修复输出。
+ 这是一个非常有用的功能,可以处理 LLM 输出格式不正确的情况。
+ 工作原理:
+ 1. 首先尝试使用基础解析器解析输出
+ 2. 如果解析失败,将错误信息和原始输出发送给 LLM
+ 3. LLM 根据格式说明修复输出
+ 4. 再次尝试解析修复后的输出
+ 5. 可以设置最大重试次数
+ """
# 初始化方法,保存基础解析器、修复链和最大重试次数
+ def __init__(
+ self,
+ parser: BaseOutputParser,
+ retry_chain,
+ max_retries: int = 1,
+ ):
+ """
+ 初始化 OutputFixingParser
+ Args:
+ parser: 基础解析器
+ retry_chain: 用于修复输出的链(通常是 Prompt -> LLM -> StrOutputParser)
+ max_retries: 最大重试次数
+ """
+ self.parser = parser
+ self.retry_chain = retry_chain
+ self.max_retries = max_retries
# 从 LLM 创建 OutputFixingParser 的类方法
+ @classmethod
+ def from_llm(
+ cls,
+ llm,
+ parser: BaseOutputParser,
+ prompt=None,
+ max_retries: int = 1,
+ ):
+ """
+ 从 LLM 创建 OutputFixingParser
+ Args:
+ llm: 用于修复输出的语言模型
+ parser: 基础解析器
+ prompt: 修复提示模板(可选,有默认模板)
+ max_retries: 最大重试次数
+ Returns:
+ OutputFixingParser 实例
+ """
# 如果没有提供 prompt,则使用默认修复模板
+ fix_template = """你是一个专门修复 LLM 输出格式的助手。
+ 原始输出:
+ {completion}
+ 出现的错误:
+ {error}
+ 输出应该遵循的格式:
+ {instructions}
+ 请修复原始输出,使其符合要求的格式。
+ 只返回修复后的输出,不要添加任何解释。"""
+ # 利用模板生成 PromptTemplate 实例
+ prompt = PromptTemplate.from_template(fix_template)
# 创建修复链,使用 SimpleChain 连接 Prompt、LLM、StrOutputParser
+ retry_chain = SimpleChain(prompt, llm, StrOutputParser())
# 返回 OutputFixingParser 实例
+ return cls(parser=parser, retry_chain=retry_chain, max_retries=max_retries)
# 解析输出,如果失败则尝试自动修复
+ def parse(self, completion: str):
+ """
+ 解析输出,如果失败则尝试修复
+ Args:
+ completion: LLM 的输出文本
+ Returns:
+ T: 解析后的结果
+ Raises:
+ OutputParserException: 如果修复后仍然无法解析
+ """
# 初始化重试次数
+ retries = 0
# 当重试次数未超过最大值时循环
+ while retries <= self.max_retries:
+ try:
# 尝试使用基础解析器解析
+ return self.parser.parse(completion)
+ except (ValueError, OutputParserException, Exception) as e:
# 如果已达到最大重试次数,抛出异常
+ if retries >= self.max_retries:
+ raise OutputParserException(
+ f"解析失败,已重试 {retries} 次: {e}",
+ llm_output=completion
+ )
# 增加重试次数
+ retries += 1
# 打印当前修复尝试次数
+ print(f" 第 {retries} 次尝试修复...")
# 获取格式说明,通常来自基础解析器
+ instructions = self.parser.get_format_instructions()
# 利用 retry_chain 调用 LLM 修复输出
+ completion = self.retry_chain.invoke({
+ "instructions": instructions,
+ "completion": completion,
+ "error": str(e),
+ })
# 如果重试后仍然失败,抛出异常
+ raise OutputParserException(
+ f"解析失败,已重试 {self.max_retries} 次",
+ llm_output=completion
+ )
# 获取格式说明的方法,委托给基础解析器
+ def get_format_instructions(self) -> str:
+ """
+ 获取格式说明(委托给基础解析器)
+ Returns:
+ str: 格式说明文本
+ """
+ try:
# 尝试调用基础解析器的 get_format_instructions 方法
+ return self.parser.get_format_instructions()
+ except (AttributeError, NotImplementedError):
# 如果没有该方法,返回默认提示
+ return "请确保输出格式正确。"19.3 类 #
19.3.1 类说明 #
| 类名 | 主要功能 | 主要方法/属性 |
|---|---|---|
| ChatOpenAI | 封装与 OpenAI 聊天模型的交互,用于调用大语言模型生成回复 | • __init__(model, **kwargs) - 初始化,指定模型名称• invoke(input, **kwargs) - 调用模型生成回复,返回 AIMessage• model - 模型名称属性• _convert_input(input) - 私有方法,将输入转换为 API 需要的消息格式 |
| JsonOutputParser | JSON 输出解析器,将 LLM 的输出解析为 JSON 对象,支持 Markdown 代码块格式 | • __init__() - 初始化解析器• parse(text) - 解析 JSON 输出文本,返回 Python 对象• get_format_instructions() - 获取格式说明,用于指导 LLM 输出 JSON 格式 |
| OutputFixingParser | 输出修复解析器,包装基础解析器,当解析失败时使用 LLM 自动修复输出 | • __init__(parser, retry_chain, max_retries) - 初始化,接收基础解析器、修复链和最大重试次数• from_llm(llm, parser, prompt, max_retries) - 类方法,从 LLM 创建修复解析器• parse(completion) - 解析输出,失败时尝试修复• get_format_instructions() - 获取格式说明(委托给基础解析器)• parser - 基础解析器属性• retry_chain - 修复链属性(SimpleChain)• max_retries - 最大重试次数属性 |
| BaseOutputParser | 输出解析器的抽象基类,定义解析器接口规范(间接使用) | • parse(text) - 抽象方法,子类必须实现• get_format_instructions() - 可选方法,获取格式说明 |
| StrOutputParser | 字符串输出解析器,将输出解析为字符串(间接使用) | • parse(text) - 解析输出文本,返回字符串• __repr__() - 返回解析器的字符串表示 |
| PromptTemplate | 提示词模板类,用于格式化字符串模板(间接使用) | • __init__(template, partial_variables) - 初始化模板实例• from_template(template) - 类方法,从模板字符串创建实例• format(**kwargs) - 格式化填充模板中的变量,返回字符串 |
| SimpleChain | 简单的链式调用包装类,连接 Prompt、LLM 和 Parser(间接使用) | • __init__(prompt, llm, parser) - 初始化,保存 prompt、llm 和 parser• invoke(input_dict) - 调用链,接收输入字典,返回解析结果• run(**kwargs) - 兼容旧接口的运行方法• prompt - 提示模板属性• llm - 语言模型属性• parser - 解析器属性 |
| OutputParserException | 输出解析异常类,继承自 ValueError(间接使用) | • __init__(message, llm_output) - 初始化,保存异常信息和 LLM 输出• llm_output - LLM 输出属性 |
19.3.2 类关系图 #
19.3.3 调用关系图 #
19.3.4 数据流转 #
初始化阶段
- 创建
ChatOpenAI实例 - 创建
JsonOutputParser实例 - 使用
OutputFixingParser.from_llm()创建修复解析器
- 创建
from_llm()方法流程- 创建修复提示模板:使用默认的修复模板创建
PromptTemplate - 创建字符串解析器:创建
StrOutputParser实例 - 创建修复链:使用
SimpleChain连接PromptTemplate、ChatOpenAI和StrOutputParser - 返回修复解析器实例
- 创建修复提示模板:使用默认的修复模板创建
解析流程(
parse()方法)- 第一次尝试:使用基础解析器(
JsonOutputParser)解析输出 - 如果失败:
- 检查重试次数是否超过限制
- 获取格式说明:调用
parser.get_format_instructions() - 调用修复链:使用
retry_chain.invoke()修复输出 - 修复链内部:
- 格式化修复提示词(包含格式说明、原始输出、错误信息)
- 调用 LLM 生成修复后的输出
- 使用
StrOutputParser解析 LLM 回复
- 使用修复后的输出再次尝试解析
- 重复上述过程,最多重试
max_retries次 - 如果仍然失败,抛出
OutputParserException
- 第一次尝试:使用基础解析器(
修复提示词模板
Instructions: -------------- {instructions} # 来自基础解析器的格式说明 -------------- Completion: -------------- {completion} # 原始输出 -------------- 上面的 Completion 没有满足 Instructions 中的约束要求。 错误信息: -------------- {error} # 解析错误信息 -------------- 请修复输出,确保它满足 Instructions 中的所有约束要求。 只返回修复后的输出,不要包含其他内容:
20.RetryOutputParser #
RetryOutputParser 是一个“鲁棒性增强”输出解析器,主要用于大语言模型输出时,基础解析器(如 JsonOutputParser)无法直接解析模型返回结果的场景。该类通过“自动重试”机制,在解析失败时,会自动调用 LLM 重新生成输出,并最多执行指定次数(max_retries)的重试,从而极大提升了解析鲁棒性和实际可用性。
核心功能
嵌套解析机制
RetryOutputParser 内部维护一个“基础解析器”(如 JsonOutputParser),每次解析首先尝试用基础解析器处理输出。如果解析失败,则自动启动重试机制。自动化重试
每次解析失败后,RetryOutputParser 会调用一个“重试链(retry_chain)”:- 将原始 prompt 及出错的 completion(模型输出)组合成一个新的提示讯息(见下方重试模板)。
- 使用 LLM 生成新输出(让模型纠正自己的输出)。
- 使用 StrOutputParser 保证模型回复为字符串类型。
最大重试次数限制
如果在设定的最大重试次数内始终无法解析成功,则抛出 OutputParserException,返回最后一次出错内容。
工作流程
- 用户提供“原始 prompt”(PromptTemplate 格式化后的字符串,通常用 StringPromptValue 包裹)。
- 首次解析,直接用基础解析器对模型输出解析。
- 如果解析失败,则构建重试提示词,调用 retry_chain.invoke() 用 LLM 生成新的输出,并再尝试解析。
- 如还失败则继续上述重试,直至达到最大次数或解析成功。
重试提示词模板示例
Prompt:
{prompt}
Completion:
{completion}
上面的 Completion 没有满足 Prompt 中的约束要求。
请重新生成一个满足要求的输出:应用场景
- 当 LLM 可能偶尔输出格式不规范、内容不完整,导致固定 parser 解析失败时,RetryOutputParser 可提升解析的成功率,减少人工干预。
- 可与任意实现了基础解析器协议(parse/get_format_instructions)的解析器组合使用(如解析 JSON、XML、结构化文本等)。
通过这种机制,可以极大提升 LLM 驱动的应用系统对于复杂格式/结构输出的容错与健壮性,特别适用于面向生产环境的调用。
20.1. prompt_values.py #
smartchain/prompt_values.py
from abc import ABC, abstractmethod
class PromptValue(ABC):
@abstractmethod
def to_string(self) -> str:
"""Return prompt value as string."""
class StringPromptValue(PromptValue):
"""String prompt value."""
def __init__(self, text: str):
self.text = text
def to_string(self) -> str:
"""返回提示词字符串"""
return self.text20.2. 20.RetryOutputParser.py #
20.RetryOutputParser.py
#from langchain_core.prompts import PromptTemplate
#from langchain_openai import ChatOpenAI
#from langchain_core.output_parsers import JsonOutputParser
#from langchain_classic.output_parsers import RetryOutputParser
#from langchain_core.prompt_values import StringPromptValue
# 导入 smartchain 的类
+from smartchain.chat_models import ChatOpenAI
+from smartchain.prompts import PromptTemplate
+from smartchain.output_parsers import RetryOutputParser, JsonOutputParser
+from smartchain.prompt_values import StringPromptValue
+import json
# 创建模型
+llm = ChatOpenAI(model="gpt-4o")
# 创建基础解析器
+json_parser = JsonOutputParser()
# 创建重试解析器
+retry_parser = RetryOutputParser.from_llm(
+ llm=llm,
+ parser=json_parser,
+ max_retries=2,
+)
# 创建提示模板
+prompt = PromptTemplate.from_template(
+ """请以 JSON 格式输出以下信息:
+ - 姓名:{name}
+ - 年龄:{age}
+ - 城市:{city}
+ {format_instructions}
+ 请输出 JSON:"""
+)
# 格式化提示词
+formatted_prompt = prompt.format(
+ name="张三",
+ age=30,
+ city="北京",
+ format_instructions=json_parser.get_format_instructions()
+)
# 模拟一个格式不正确的 LLM 输出
+invalid_completion = 'name: "张三", age: 30, city: "北京"' # 不是有效的 JSON
+try:
# 直接使用基础解析器(应该失败)
+ try:
+ result = json_parser.parse(invalid_completion)
+ print(f"基础解析器:解析成功(意外)")
+ except Exception as e:
+ print(f"基础解析器:解析失败 X")
+ print(f" 错误:{type(e).__name__}: {e}")
+ prompt_value = StringPromptValue(text=formatted_prompt)
+ result = retry_parser.parse_with_prompt(invalid_completion, prompt_value)
+ print(f" 重试后解析成功!")
+ print(f" 结果:{json.dumps(result, ensure_ascii=False, indent=2)}")
+except Exception as e:
+ print(f" 重试失败:{type(e).__name__}: {e}")
20.3. output_parsers.py #
smartchain/output_parsers.py
# 导入抽象类基类(ABC)和抽象方法(abstractmethod)
from abc import ABC, abstractmethod
import json
import re
import pydantic
from .prompts import PromptTemplate
# 定义输出解析器的抽象基类
class BaseOutputParser(ABC):
"""输出解析器的抽象基类"""
# 定义抽象方法 parse,需要子类实现具体的解析逻辑
@abstractmethod
def parse(self, text):
"""
解析输出文本
Args:
text: 要解析的文本
Returns:
解析后的结果
"""
# 抽象方法体,实际不会执行,只是作为接口约束
pass
# 定义字符串输出解析器类,继承自 BaseOutputParser
class StrOutputParser(BaseOutputParser):
"""
字符串输出解析器
将 LLM 的输出解析为字符串。这是最简单的输出解析器,
它不会修改输入内容,只是确保输出是字符串类型。
主要用于:
- 确保 LLM 输出是字符串类型
- 在链式调用中统一输出格式
- 简化输出处理流程
"""
# 实现 parse 方法,将输入内容原样返回为字符串
def parse(self, text: str) -> str:
"""
解析输出文本(实际上只是返回原文本)
Args:
text: 输入文本(应该是字符串)
Returns:
str: 原样返回输入文本
"""
# 如果输入不是字符串,则将其转换为字符串类型
if not isinstance(text, str):
return str(text)
# 如果已经是字符串,则直接返回
return text
# 定义 __repr__ 方法,返回该解析器的字符串表示
def __repr__(self) -> str:
"""返回解析器的字符串表示"""
return "StrOutputParser()"
# 定义一个辅助函数:从文本中提取 JSON(支持 markdown 代码块)
def parse_json_markdown(text):
"""
从文本中解析 JSON,支持 markdown 代码块格式
Args:
text: 可能包含 JSON 的文本
Returns:
解析后的 JSON 对象
Raises:
json.JSONDecodeError: 如果无法解析 JSON
"""
# 去除 text 字符串首尾的空白字符
text = text.strip()
# 正则匹配 markdown 代码块中的 JSON,如 ``json ... `` 或 `` ... ``
json_match = re.search(r'``(?:json)?\s*\n?(.*?)\n?``', text, re.DOTALL)
# 如果找到 markdown 代码块匹配
if json_match:
# 提取代码块内容并去除首尾空白
text = json_match.group(1).strip()
# 再次匹配文本里的 { ... } 或 [ ... ] 结构
json_match = re.search(r'(\{.*\}|$$.*$$)', text, re.DOTALL)
# 如果找到大括号(对象)或中括号(数组)包裹的 JSON
if json_match:
# 提取 JSON 主体内容
text = json_match.group(1)
# 用 json.loads 解析 JSON 字符串,返回 Python 对象
return json.loads(text)
# 定义一个 JSON 输出解析器类,继承自 BaseOutputParser
class JsonOutputParser(BaseOutputParser):
"""
JSON 输出解析器
将 LLM 的输出解析为 JSON 对象。支持:
- 纯 JSON 字符串
- Markdown 代码块中的 JSON(``json ... ``)
- 包含 JSON 的文本(自动提取)
主要用于:
- 结构化数据提取
- API 响应解析
- 数据格式化
"""
# 构造方法,初始化解析器对象
def __init__(self):
"""
初始化 JsonOutputParser
"""
pass
# 解析输入文本为 JSON 对象
def parse(self, text):
"""
解析 JSON 输出文本
Args:
text: 包含 JSON 的文本
Returns:
Any: 解析后的 JSON 对象(字典、列表等)
Raises:
ValueError: 如果无法解析 JSON
"""
try:
# 使用辅助函数 parse_json_markdown 解析文本内容
parsed = parse_json_markdown(text)
# 返回解析结果
return parsed
# 捕获 json 格式错误,包装成 ValueError 抛出
except json.JSONDecodeError as e:
raise ValueError(f"无法解析 JSON 输出: {text[:100]}... 错误: {e}")
# 捕获其他异常,也包装成 ValueError 抛出
except Exception as e:
raise ValueError(f"解析 JSON 时出错: {e}")
# 返回给 LLM 的 JSON 输出格式要求指导语
def get_format_instructions(self) -> str:
"""
获取格式说明,用于在提示词中指导 LLM 输出 JSON 格式
Returns:
str: 格式说明文本
"""
# 返回关于如何格式化 JSON 输出的说明
return """请以 JSON 格式输出你的回答。
输出格式要求:
1. 使用有效的 JSON 格式
2. 可以使用 markdown 代码块包裹:``json ... ``
3. 确保所有字符串都用双引号
4. 确保 JSON 格式正确且完整
示例格式:
``json
{
"key": "value",
"number": 123
}
``"""
# 定义 Pydantic 输出解析器类,继承自 JsonOutputParser
class PydanticOutputParser(JsonOutputParser):
# 用于 Pydantic 输出解析器的类注释
"""
Pydantic 输出解析器
将 LLM 的输出解析为 Pydantic 模型实例。继承自 JsonOutputParser,
先解析 JSON,然后验证并转换为 Pydantic 模型。
主要用于:
- 结构化数据验证
- 类型安全的数据提取
- 自动数据验证和转换
"""
# 构造函数,初始化 PydanticOutputParser
def __init__(self, pydantic_object: type):
# 调用父类 JsonOutputParser 的构造方法
super().__init__()
# 保存用户传入的 Pydantic 模型类
self.pydantic_object = pydantic_object
# 解析函数,将文本解析为 Pydantic 实例
def parse(self, text: str):
# 尝试解析并转换文本为 Pydantic 实例
try:
# 首先用父类方法将文本解析为 JSON 对象(如 dict)
json_obj = super().parse(text)
# 将 JSON 对象转为 Pydantic 模型实例
return self._parse_obj(json_obj)
# 捕获并包装所有异常为 ValueError
except Exception as e:
raise ValueError(f"无法解析为 Pydantic 模型: {e}")
# 辅助方法:将字典对象转换为 Pydantic 模型实例
def _parse_obj(self, obj: dict):
# 如果模型有 model_validate 方法(Pydantic v2),优先使用
if hasattr(self.pydantic_object, 'model_validate'):
return self.pydantic_object.model_validate(obj)
# 如果模型有 parse_obj 方法(Pydantic v1),则使用
elif hasattr(self.pydantic_object, 'parse_obj'):
return self.pydantic_object.parse_obj(obj)
# 否则,尝试直接用 ** 解包初始化
else:
return self.pydantic_object(**obj)
# 私有方法,获取 Pydantic 模型的 JSON Schema
def _get_schema(self) -> dict:
# 尝试获取 schema,支持 Pydantic v1 和 v2
try:
# v2: 使用 model_json_schema 方法
if hasattr(self.pydantic_object, 'model_json_schema'):
return self.pydantic_object.model_json_schema()
# v1: 使用 schema 方法
elif hasattr(self.pydantic_object, 'schema'):
return self.pydantic_object.schema()
# 如果都没有则返回空字典
else:
return {}
# 捕获异常并返回空字典
except Exception:
return {}
# 返回格式说明,自动添加 schema 信息
def get_format_instructions(self) -> str:
# 获取 Pydantic 模型 schema
schema = self._get_schema()
# 拷贝一份 schema 进行编辑
reduced_schema = dict(schema)
# 删除 description 字段(如果有)
if "description" in reduced_schema:
del reduced_schema["description"]
# 序列化 schema 为格式化字符串
schema_str = json.dumps(reduced_schema, ensure_ascii=False, indent=2)
# 返回格式说明字符串,内嵌 JSON Schema
return f"""请以 JSON 格式输出,必须严格遵循以下 Schema:
``json
{schema_str}
``
输出要求:
1. 必须完全符合上述 Schema 结构
2. 所有必需字段都必须提供
3. 字段类型必须匹配(字符串、数字、布尔值等)
4. 使用有效的 JSON 格式
5. 可以使用 markdown 代码块包裹:``json ... ``
确保输出是有效的 JSON,并且符合 Schema 定义。"""
# 简单的链式调用包装类
class SimpleChain:
# 初始化方法,保存 prompt、llm 和 parser
def __init__(self, prompt, llm, parser):
self.prompt = prompt
self.llm = llm
self.parser = parser
# 调用链方法,接收输入字典,返回字符串
def invoke(self, input_dict: dict) -> str:
# 格式化提示词
formatted = self.prompt.format(**input_dict)
# 通过 llm 调用生成响应
response = self.llm.invoke(formatted)
# 判断响应是否有 content 属性
if hasattr(response, 'content'):
content = response.content
else:
# 若无 content 属性,则转换为字符串
content = str(response)
# 使用 parser 解析内容
return self.parser.parse(content)
# 兼容旧接口的运行方法
def run(self, **kwargs) -> str:
# 调用 invoke 方法,传入参数
return self.invoke(kwargs)
# 输出解析异常类,继承自 ValueError
class OutputParserException(ValueError):
# 初始化方法,保存异常信息和 llm 输出
def __init__(self, message: str, llm_output: str = ""):
super().__init__(message)
self.llm_output = llm_output
# 输出修复解析器类,继承自 BaseOutputParser
class OutputFixingParser(BaseOutputParser):
"""
输出修复解析器
包装一个基础解析器,当解析失败时,使用 LLM 自动修复输出。
这是一个非常有用的功能,可以处理 LLM 输出格式不正确的情况。
工作原理:
1. 首先尝试使用基础解析器解析输出
2. 如果解析失败,将错误信息和原始输出发送给 LLM
3. LLM 根据格式说明修复输出
4. 再次尝试解析修复后的输出
5. 可以设置最大重试次数
"""
# 初始化方法,保存基础解析器、修复链和最大重试次数
def __init__(
self,
parser: BaseOutputParser,
retry_chain,
max_retries: int = 1,
):
"""
初始化 OutputFixingParser
Args:
parser: 基础解析器
retry_chain: 用于修复输出的链(通常是 Prompt -> LLM -> StrOutputParser)
max_retries: 最大重试次数
"""
self.parser = parser
self.retry_chain = retry_chain
self.max_retries = max_retries
# 从 LLM 创建 OutputFixingParser 的类方法
@classmethod
def from_llm(
cls,
llm,
parser: BaseOutputParser,
prompt=None,
max_retries: int = 1,
):
"""
从 LLM 创建 OutputFixingParser
Args:
llm: 用于修复输出的语言模型
parser: 基础解析器
prompt: 修复提示模板(可选,有默认模板)
max_retries: 最大重试次数
Returns:
OutputFixingParser 实例
"""
# 如果没有提供 prompt,则使用默认修复模板
if prompt is None:
fix_template = """你是一个专门修复 LLM 输出格式的助手。
原始输出:
{completion}
出现的错误:
{error}
输出应该遵循的格式:
{instructions}
请修复原始输出,使其符合要求的格式。
只返回修复后的输出,不要添加任何解释。"""
# 利用模板生成 PromptTemplate 实例
prompt = PromptTemplate.from_template(fix_template)
# 创建修复链,使用 SimpleChain 连接 Prompt、LLM、StrOutputParser
retry_chain = SimpleChain(prompt, llm, StrOutputParser())
# 返回 OutputFixingParser 实例
return cls(parser=parser, retry_chain=retry_chain, max_retries=max_retries)
# 解析输出,如果失败则尝试自动修复
def parse(self, completion: str):
"""
解析输出,如果失败则尝试修复
Args:
completion: LLM 的输出文本
Returns:
T: 解析后的结果
Raises:
OutputParserException: 如果修复后仍然无法解析
"""
# 初始化重试次数
retries = 0
# 当重试次数未超过最大值时循环
while retries <= self.max_retries:
try:
# 尝试使用基础解析器解析
return self.parser.parse(completion)
except (ValueError, OutputParserException, Exception) as e:
# 如果已达到最大重试次数,抛出异常
if retries >= self.max_retries:
raise OutputParserException(
f"解析失败,已重试 {retries} 次: {e}",
llm_output=completion
)
# 增加重试次数
retries += 1
# 打印当前修复尝试次数
print(f" 第 {retries} 次尝试修复...")
# 获取格式说明,通常来自基础解析器
instructions = self.parser.get_format_instructions()
# 利用 retry_chain 调用 LLM 修复输出
completion = self.retry_chain.invoke({
"instructions": instructions,
"completion": completion,
"error": str(e),
})
# 如果重试后仍然失败,抛出异常
raise OutputParserException(
f"解析失败,已重试 {self.max_retries} 次",
llm_output=completion
)
# 获取格式说明的方法,委托给基础解析器
def get_format_instructions(self) -> str:
"""
获取格式说明(委托给基础解析器)
Returns:
str: 格式说明文本
"""
try:
# 尝试调用基础解析器的 get_format_instructions 方法
return self.parser.get_format_instructions()
except (AttributeError, NotImplementedError):
# 如果没有该方法,返回默认提示
return "请确保输出格式正确。"
# 定义重试输出解析器类
+class RetryOutputParser(BaseOutputParser):
+ """
+ 重试输出解析器
+ 包装一个基础解析器,当解析失败时,使用 LLM 重新生成输出。
+ 与 OutputFixingParser 的区别:
+ - RetryOutputParser 需要原始 prompt 和 completion
+ - 它使用 parse_with_prompt 方法而不是 parse 方法
+ - 它将原始 prompt 和 completion 都传递给 LLM,让 LLM 重新生成
+ 工作原理:
+ 1. 首先尝试使用基础解析器解析 completion
+ 2. 如果解析失败,将原始 prompt 和 completion 发送给 LLM
+ 3. LLM 根据 prompt 的要求重新生成输出
+ 4. 再次尝试解析新生成的输出
+ 5. 可以设置最大重试次数
+ """
+ def __init__(
+ self,
+ parser: BaseOutputParser,
+ retry_chain,
+ max_retries: int = 1,
+ ):
+ """
+ 初始化 RetryOutputParser
+ Args:
+ parser: 基础解析器
+ retry_chain: 用于重试的链(通常是 Prompt -> LLM -> StrOutputParser)
+ max_retries: 最大重试次数
+ """
+ self.parser = parser
+ self.retry_chain = retry_chain
+ self.max_retries = max_retries
+ @classmethod
+ def from_llm(
+ cls,
+ llm,
+ parser: BaseOutputParser,
+ prompt=None,
+ max_retries: int = 1,
+ ) -> "RetryOutputParser":
+ """
+ 从 LLM 创建 RetryOutputParser
+ Args:
+ llm: 用于重试的语言模型
+ parser: 基础解析器
+ prompt: 重试提示模板(可选,有默认模板)
+ max_retries: 最大重试次数
+ Returns:
+ RetryOutputParser 实例
+ """
+ from .prompts import PromptTemplate
# 默认重试提示模板
+ if prompt is None:
+ retry_template = """Prompt:
+ {prompt}
+ Completion:
+ {completion}
+ 上面的 Completion 没有满足 Prompt 中的约束要求。
+ 请重新生成一个满足要求的输出:"""
+ prompt = PromptTemplate.from_template(retry_template)
# 创建重试链:Prompt -> LLM -> StrOutputParser
+ retry_chain = SimpleChain(prompt, llm, StrOutputParser())
+ return cls(parser=parser, retry_chain=retry_chain, max_retries=max_retries)
+ def parse_with_prompt(self, completion: str, prompt_value):
+ """
+ 使用 prompt 解析输出,如果失败则尝试重试
+ Args:
+ completion: LLM 的输出文本
+ prompt_value: 原始提示词(可以是字符串或 PromptValue 对象)
+ Returns:
+ T: 解析后的结果
+ Raises:
+ OutputParserException: 如果重试后仍然无法解析
+ """
+ retries = 0
+ while retries <= self.max_retries:
+ try:
# 尝试使用基础解析器解析
+ return self.parser.parse(completion)
+ except (ValueError, OutputParserException, Exception) as e:
# 如果已达到最大重试次数,抛出异常
+ if retries >= self.max_retries:
+ raise OutputParserException(
+ f"解析失败,已重试 {retries} 次: {e}",
+ llm_output=completion
+ )
+ retries += 1
+ print(f" 第 {retries} 次尝试重试...")
# 使用 LLM 重新生成输出
+ try:
+ completion = self.retry_chain.invoke({
+ "prompt": prompt_value.to_string(),
+ "completion": completion,
+ })
+ except Exception as retry_error:
+ raise OutputParserException(
+ f"重试输出时出错: {retry_error}",
+ llm_output=completion
+ )
+ raise OutputParserException(
+ f"解析失败,已重试 {self.max_retries} 次",
+ llm_output=completion
+ )
+ def parse(self, completion: str):
+ """
+ 此解析器只能通过 parse_with_prompt 方法调用
+ Raises:
+ NotImplementedError: 总是抛出此异常
+ """
+ raise NotImplementedError(
+ "RetryOutputParser 只能通过 parse_with_prompt 方法调用,"
+ "需要提供原始 prompt。"
+ )
+ def get_format_instructions(self) -> str:
+ """
+ 获取格式说明(委托给基础解析器)
+ Returns:
+ str: 格式说明文本
+ """
+ try:
+ return self.parser.get_format_instructions()
+ except (AttributeError, NotImplementedError):
+ return "请确保输出格式正确。"
20.4 类 #
20.4.1 类说明 #
| 类名 | 主要功能 | 主要方法/属性 |
|---|---|---|
| ChatOpenAI | 封装与 OpenAI 聊天模型的交互,用于调用大语言模型生成回复 | • __init__(model, **kwargs) - 初始化,指定模型名称• invoke(input, **kwargs) - 调用模型生成回复,返回 AIMessage• model - 模型名称属性• _convert_input(input) - 私有方法,将输入转换为 API 需要的消息格式 |
| PromptTemplate | 提示词模板类,用于格式化字符串模板,支持变量替换 | • __init__(template, partial_variables) - 初始化模板实例• from_template(template) - 类方法,从模板字符串创建实例• format(**kwargs) - 格式化填充模板中的变量,返回字符串• template - 模板字符串属性• input_variables - 输入变量列表属性 |
| JsonOutputParser | JSON 输出解析器,将 LLM 的输出解析为 JSON 对象,支持 Markdown 代码块格式 | • __init__() - 初始化解析器• parse(text) - 解析 JSON 输出文本,返回 Python 对象• get_format_instructions() - 获取格式说明,用于指导 LLM 输出 JSON 格式 |
| RetryOutputParser | 重试输出解析器,包装基础解析器,当解析失败时使用 LLM 重新生成输出 | • __init__(parser, retry_chain, max_retries) - 初始化,接收基础解析器、修复链和最大重试次数• from_llm(llm, parser, prompt, max_retries) - 类方法,从 LLM 创建重试解析器• parse_with_prompt(completion, prompt_value) - 使用 prompt 解析输出,失败时尝试重试• get_format_instructions() - 获取格式说明(委托给基础解析器)• parser - 基础解析器属性• retry_chain - 重试链属性(SimpleChain)• max_retries - 最大重试次数属性 |
| StringPromptValue | 字符串提示值类,用于包装字符串格式的提示词 | • __init__(text) - 初始化,接收文本字符串• to_string() - 返回提示词字符串• text - 文本内容属性 |
| PromptValue | 提示值的抽象基类,定义提示值接口规范(间接使用) | • to_string() - 抽象方法,子类必须实现,返回字符串 |
| BaseOutputParser | 输出解析器的抽象基类,定义解析器接口规范(间接使用) | • parse(text) - 抽象方法,子类必须实现• get_format_instructions() - 可选方法,获取格式说明 |
| StrOutputParser | 字符串输出解析器,将输出解析为字符串(间接使用) | • parse(text) - 解析输出文本,返回字符串• __repr__() - 返回解析器的字符串表示 |
| SimpleChain | 简单的链式调用包装类,连接 Prompt、LLM 和 Parser(间接使用) | • __init__(prompt, llm, parser) - 初始化,保存 prompt、llm 和 parser• invoke(input_dict) - 调用链,接收输入字典,返回解析结果• prompt - 提示模板属性• llm - 语言模型属性• parser - 解析器属性 |
| OutputParserException | 输出解析异常类,继承自 ValueError(间接使用) | • __init__(message, llm_output) - 初始化,保存异常信息和 LLM 输出• llm_output - LLM 输出属性 |
20.4.2 类图 #
20.4.3 调用关系图 #

20.4.4 数据流转过程 #
初始化阶段
- 创建
ChatOpenAI实例 - 创建
JsonOutputParser实例 - 使用
RetryOutputParser.from_llm()创建重试解析器
- 创建
from_llm()方法流程- 创建重试提示模板:使用默认的重试模板创建
PromptTemplate - 创建字符串解析器:创建
StrOutputParser实例 - 创建重试链:使用
SimpleChain连接PromptTemplate、ChatOpenAI和StrOutputParser - 返回重试解析器实例
- 创建重试提示模板:使用默认的重试模板创建
提示词准备阶段
- 创建提示模板:使用
PromptTemplate.from_template()创建模板 - 获取格式说明:调用
json_parser.get_format_instructions() - 格式化提示词:使用
prompt.format()填充变量 - 创建提示值对象:使用
StringPromptValue包装格式化后的提示词
- 创建提示模板:使用
解析流程(
parse_with_prompt()方法)- 第一次尝试:使用基础解析器(
JsonOutputParser)解析输出 - 如果失败:
- 检查重试次数是否超过限制
- 获取原始 prompt:调用
prompt_value.to_string() - 调用重试链:使用
retry_chain.invoke()重新生成输出 - 重试链内部:
- 格式化重试提示词(包含原始 prompt、原始 completion)
- 调用 LLM 根据原始 prompt 重新生成输出
- 使用
StrOutputParser解析 LLM 回复
- 使用新生成的输出再次尝试解析
- 重复上述过程,最多重试
max_retries次 - 如果仍然失败,抛出
OutputParserException
- 第一次尝试:使用基础解析器(
重试提示词模板
Prompt: {prompt} # 原始提示词 Completion: {completion} # 原始输出 上面的 Completion 没有满足 Prompt 中的约束要求。 请重新生成一个满足要求的输出:
21.BaseOutputParser #
设计思想
BaseOutputParser是输出解析器体系的抽象父类,设计的核心目的是实现结构化输出解析:将大语言模型(LLM)输出的自然语言文本,可靠地转换为 Python 结构化对象(如bool、dict、list等),并对异常情况提供统一的处理方法。- 这种抽象使得开发者可以针对具体需求,实现不同的解析器,而不用重复编写通用的异常捕获和接口定义逻辑。
主要接口
一个典型的 BaseOutputParser 派生类需要实现如下关键方法:
parse(self, text: str) -> Any解析 LLM 输出内容。子类负责将
text转换为目标类型(如布尔值、JSON对象等)。如果解析失败,应抛出OutputParserException,方便自动重试与错误追踪。get_format_instructions(self) -> str返回一段字符串,描述 LLM 应该如何格式化输出。这一接口常用于提示词工程,即“告知”模型输出什么形态的内容,以便后续解析器正确处理。
这些方法的设计极大增强了代码复用性和健壮性。在 LLM 的应用流程中,先通过 get_format_instructions() 生成格式约束的 prompt,引导模型输出可解析的内容,然后用 parse() 将输出转为目标结构。
典型应用场景
- 布尔值解析:如示例中的
BooleanOutputParser,可用于二分类决策、判别题等场景,模型只需输出 YES/NO、True/False、是/否等,经解析器统一转换为True或False。 - 结构化数据提取:如读取模型输出的 JSON/XML,将其安全转为 Python 对象,用于后续逻辑处理。
- 错误处理与提示强化:结合
OutputParserException及重试机制,可以在解析失败时自动回退、再生成,有效提高整体容错率。
实践意义
- 有效防止 LLM 输出不一致、乱格式、冗余内容带来的解析难题。
- 为 prompt 设计、解析逻辑解耦,提升代码维护性和可测试性。
- 支持高级能力如流式解析、异常追踪、多种输出格式融合。
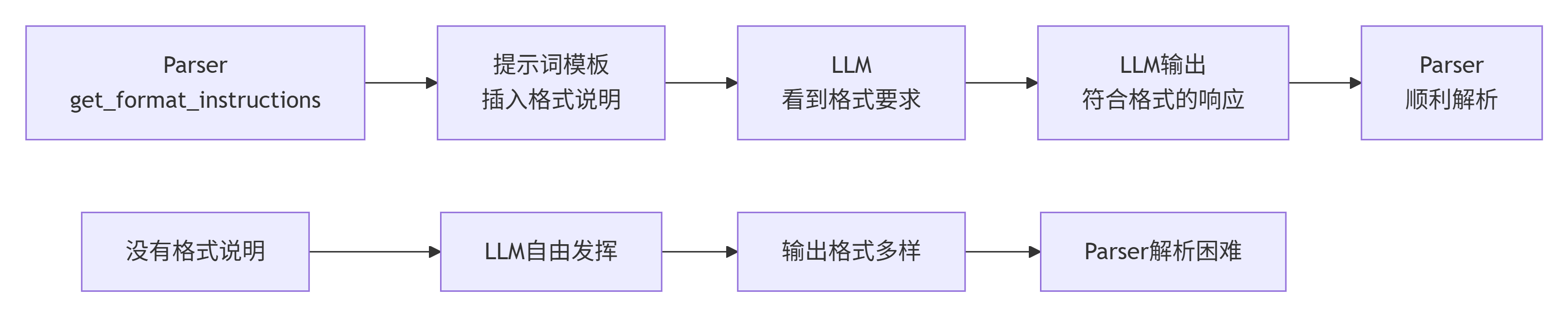
21.1. 21.BaseOutputParser.py #
21.BaseOutputParser.py
#from langchain_core.prompts import PromptTemplate
#from langchain_openai import ChatOpenAI
#from langchain_core.output_parsers import BaseOutputParser
#from langchain_core.exceptions import OutputParserException
# 从 smartchain 库导入 PromptTemplate
from smartchain.prompts import PromptTemplate
# 从 smartchain 库导入 ChatOpenAI
from smartchain.chat_models import ChatOpenAI
# 从 smartchain 库导入 BaseOutputParser 和 OutputParserException
from smartchain.output_parsers import BaseOutputParser, OutputParserException
# 定义布尔值输出解析器类,继承自 BaseOutputParser
class BooleanOutputParser(BaseOutputParser):
"""
布尔值输出解析器
将文本解析为布尔值。支持多种表示方式:
- YES/NO
- TRUE/FALSE
- 是/否
- 1/0
"""
# 初始化方法,可选指定代表 True 和 False 的字符串
def __init__(self, true_val: str = "YES", false_val: str = "NO"):
"""
初始化布尔值解析器
Args:
true_val: 表示 True 的值(默认 "YES")
false_val: 表示 False 的值(默认 "NO")
"""
# 调用父类初始化方法,若抛出 TypeError 则忽略
try:
super().__init__()
except TypeError:
pass # 如果父类不需要参数
# 设置 true_val 属性,转换为大写
object.__setattr__(self, 'true_val', true_val.upper())
# 设置 false_val 属性,转换为大写
object.__setattr__(self, 'false_val', false_val.upper())
# 定义解析方法,将文本转为布尔值
def parse(self, text: str) -> bool:
"""
解析文本为布尔值
Args:
text: 要解析的文本
Returns:
bool: 解析后的布尔值
Raises:
OutputParserException: 如果无法解析为布尔值
"""
# 去除首尾空白并转为大写
cleaned_text = text.strip().upper()
# 定义表示 True 的所有可能取值
true_values = [self.true_val, "TRUE", "YES", "是", "1", "Y"]
# 定义表示 False 的所有可能取值
false_values = [self.false_val, "FALSE", "NO", "否", "0", "N"]
# 如果解析后的文本在 true_values 中,则返回 True
if cleaned_text in true_values:
return True
# 如果解析后的文本在 false_values 中,则返回 False
elif cleaned_text in false_values:
return False
# 否则抛出解析异常,给出期望的值
else:
raise OutputParserException(
f"BooleanOutputParser 无法解析 '{text}'。"
f"期望的值:{true_values} 或 {false_values}"
)
# 告诉 LLM 应该输出什么样的格式,用于构造提示词的"格式说明"部分
def get_format_instructions(self) -> str:
# 返回格式说明,告知只输出 true_val 或 false_val
return f"请输出 {self.true_val} 或 {self.false_val}(不区分大小写)"
# 构建一个布尔值解析器实例
bool_parser = BooleanOutputParser()
# 构建测试用例列表
test_cases = [
"YES",
"no",
"true",
"FALSE",
"是",
"否",
"1",
"0",
]
# 遍历所有测试用例,运行解析器并打印结果
for test in test_cases:
result = bool_parser.parse(test)
print(f" '{test}' -> {result}")
# 创建一个 LLM(大语言模型)实例,指定模型为 "gpt-4o"
llm = ChatOpenAI(model="gpt-4o")
# 创建一个带有格式化说明的布尔判断提示模板
bool_prompt = PromptTemplate.from_template(
"""判断以下陈述是否正确。
陈述:{statement}
{format_instructions}
请回答:"""
)
# 定义要判断的陈述内容
statement = "Python 是一种编程语言"
# 用指定陈述和格式说明格式化 prompt
formatted = bool_prompt.format(
statement=statement,
format_instructions=bool_parser.get_format_instructions()
)
# 调用 LLM,获取结果
response = llm.invoke(formatted)
# 打印陈述和 LLM 输出内容
print(f" 陈述: {statement}")
print(f" LLM 输出: {response.content}")
# 尝试用布尔解析器解析 LLM 输出内容
try:
result = bool_parser.parse(response.content)
print(f" 解析结果: {result}")
# 出现异常时打印错误信息
except Exception as e:
print(f" 解析错误: {e}")
21.2. 类 #
21.2.1 类说明 #
| 类名 | 主要功能 | 关键方法 | 在代码中的使用 |
|---|---|---|---|
| BaseExampleSelector | 示例选择器的抽象基类 | select_examples(input_variables: dict) (抽象方法) |
第10行:导入;第18行:作为 KeywordBasedExampleSelector 的父类 |
| KeywordBasedExampleSelector | 基于关键词匹配的示例选择器 | __init__(), select_examples(), _extract_keywords(), _calculate_match_score() |
第18-142行:定义;第164行:创建实例;在 FewShotPromptTemplate 中使用 |
| PromptTemplate | 字符串模板格式化类 | __init__(), from_template(), format() |
第9行:导入;第159行:创建示例格式化模板 |
| FewShotPromptTemplate | 构建 few-shot 提示词模板 | __init__(), format(), format_examples() |
第9行:导入;第172行:创建 few-shot 模板;第182行:格式化完整提示词 |
| ChatOpenAI | 与大语言模型对话的封装类 | __init__(), invoke(), stream() |
第8行:导入;第187行:创建模型实例;第189行:调用模型生成回复 |
21.2.2 类图 #
21.2.3 时序图 #
21.2.4 调用过程 #
21.2.4.1 初始化阶段 #
步骤1:创建示例格式化模板(第159-161行)
example_prompt = PromptTemplate.from_template(
"问题:{question}\n答案:{answer}"
)- 创建
PromptTemplate,用于格式化每个示例
步骤2:创建自定义示例选择器(第164-169行)
keyword_selector = KeywordBasedExampleSelector(
examples=examples,
k=3,
input_key="question",
min_keyword_match=1,
)KeywordBasedExampleSelector.__init__() 流程:
- 保存示例列表:
self.examples = examples - 设置参数:
k=3:选择 3 个示例input_key="question":从输入变量中取question字段min_keyword_match=1:至少匹配 1 个关键词
步骤3:创建 Few-Shot 模板(第172-177行)
few_shot_prompt = FewShotPromptTemplate(
example_prompt=example_prompt,
prefix="你是一个乐于助人的生活小助手。以下是一些建议示例:",
suffix="问题:{question}\n答案:",
example_selector=keyword_selector,
)- 保存
example_selector引用,用于动态选择示例
21.2.4.2 运行时阶段 #
步骤1:格式化提示词
formatted = few_shot_prompt.format(question=user_question)步骤2:选择示例
当 FewShotPromptTemplate.format_examples() 被调用时:
if self.example_selector:
selected_examples = self.example_selector.select_examples(input_variables)步骤3:关键词提取和匹配
详细流程:
获取输入文本(第114行):
input_text = input_variables.get(self.input_key, "") # input_text = "手机没信号怎么办?"提取输入关键词(第96行调用
_extract_keywords()):def _extract_keywords(self, text: str): keywords = set() words = jieba.cut(text) # 使用jieba分词 for word in words: word = word.strip() if re.match(r'^[\u4e00-\u9fa5]+$', word) and len(word) > 1: keywords.add(word) # 中文关键词 elif re.match(r'^[a-zA-Z]+$', word): keywords.add(word.lower()) # 英文关键词 return keywords- 输入:"手机没信号怎么办?"
- 提取关键词:
{"手机", "信号"}
遍历示例并计算匹配分数(第121-128行):
for example in self.examples: example_text = example.get(self.input_key, "") score = self._calculate_match_score(input_text, example_text) if score >= self.min_keyword_match: scored_examples.append((score, example))计算匹配分数(
_calculate_match_score()方法,第84-100行):def _calculate_match_score(self, input_text: str, example_text: str) -> int: input_keywords = self._extract_keywords(input_text) example_keywords = self._extract_keywords(example_text) return len(input_keywords & example_keywords) # 集合交集示例匹配:
- 示例1:"手机没电了怎么办?" → 关键词:
{"手机"}→ 匹配分数:1 - 示例2:"怎么做西红柿炒鸡蛋?" → 关键词:
{"西红柿", "鸡蛋"}→ 匹配分数:0 - 示例3:"今天天气怎么样?" → 关键词:
{"天气"}→ 匹配分数:0
- 示例1:"手机没电了怎么办?" → 关键词:
排序并选择 top-k(第131-134行):
scored_examples.sort(key=lambda x: x[0], reverse=True) # 按分数降序 selected = [example for _, example in scored_examples[:self.k]]- 选择匹配分数最高的 3 个示例
补齐不足的示例(第137-139行):
if len(selected) < self.k: remaining = [ex for ex in self.examples if ex not in selected] selected.extend(remaining[:self.k - len(selected)])
步骤4:格式化示例并拼接
格式化每个选中示例(调用
example_prompt.format()):for example in selected_examples: formatted.append(self.example_prompt.format(**example))拼接完整提示词:
prefix + 格式化示例1 + 格式化示例2 + 格式化示例3 + suffix
步骤5:调用大语言模型
result = llm.invoke(formatted)ChatOpenAI.invoke() 流程:
_convert_input()将字符串转换为 OpenAI 消息格式- 调用 OpenAI API
- 解析响应,返回
AIMessage对象
21.2.4.3 核心算法 #
关键词提取算法
使用 jieba 分词,提取规则:
- 中文关键词:全为中文且长度 > 1
- 英文关键词:全为字母,转为小写
匹配分数计算
使用集合交集计算重叠关键词数量:
$$\text{score} = |K_{\text{input}} \cap K_{\text{example}}|$$
其中:
- $K_{\text{input}}$ 是输入文本的关键词集合
- $K_{\text{example}}$ 是示例文本的关键词集合
示例选择策略
- 计算所有示例的匹配分数
- 过滤:
score >= min_keyword_match - 按分数降序排序
- 选择 top-k 个示例
- 若不足 k 个,从剩余示例中补齐
21.3 数据流转图 #
原始示例列表 (examples)
↓
[KeywordBasedExampleSelector.__init__]
↓
保存示例列表和参数
↓
[用户查询] → 提取关键词 → 计算匹配分数 → 排序选择top-k
↓
选中3个示例
↓
[FewShotPromptTemplate.format]
↓
格式化示例 (PromptTemplate.format)
↓
拼接prefix + examples + suffix
↓
完整提示词字符串
↓
[ChatOpenAI.invoke]
↓
AI回复 (AIMessage)21.4 与 SemanticSimilarityExampleSelector 的对比 #
| 特性 | KeywordBasedExampleSelector | SemanticSimilarityExampleSelector |
|---|---|---|
| 匹配方式 | 关键词重叠(集合交集) | 语义相似度(向量余弦相似度) |
| 依赖 | jieba 分词库 | OpenAI Embeddings + FAISS |
| 计算复杂度 | O(n×m)(n=示例数,m=平均关键词数) | O(n×d)(d=向量维度,通常更高) |
| 准确性 | 基于字面匹配,可能遗漏语义相似 | 基于语义理解,更准确 |
| 性能 | 快速,无需 API 调用 | 较慢,需要向量化 API 调用 |
| 适用场景 | 关键词明确、快速响应 | 语义理解要求高、示例量大 |